浏览器和Node中的JavaScript是如何工作的? 可视化解释
原文地址: How JavaScript works in browser and node?
有非常多满怀激情的开发者,他们搞前端或者搞后端,为JavaScript奉献自己青春和血汗。JavaScript是一种非常容易理解语言,毫无疑问它是前端开发中一个非常关键的部分。但是和其他语言不同的是, 它是单线程的,这就意味着,同一时间只能有一个代码片段在执行。因为代码执行是线性的,如果当中有任何代码执行很长时间,将会阻塞后面需要被执行的代码。因此有时候你会在Google Chrome中看到这样的界面:
当你在浏览器打开一个网站时,它会使用一个JavaScript执行线程。这个线程负责响应一切操作,比如页面滚动、页面渲染、监听DOM事件(比如用户点击按钮)等等。但是如果JavaScript执行被阻塞了,那浏览器就什么事情也做不了,即意味着浏览器会呈现为卡死,无法响应的现象。
不信你就在控制台输入试试:
while(true){} |
你会上面语句之后的任何代码都不会被执行,这个‘死循环’会霸占着系统资源, 让浏览器无法响应用户操作. 无限递归调用也会出现这种情况, 不过下文会介绍,Javascript引擎对调用栈长度进行限制,无限递归会抛出RangeError异常, 而不会无休止地运行。
感谢现代浏览器,现在不是所有打开的标签页都依赖于一个JavaScript线程。而是每个标签页或者域名都会有独立的JavaScript线程。这样每个标签页之间不会互相阻塞。比如你可以在Chrome中打开多个标签页,在某个标签页下执行上面的死循环,你会发现只有执行了上面语句的标签卡死,其他不受影响。
调用栈(Call Stack)
为了可视化JavaScript 如何执行程序,我们首先要理解JavaScript运行时。
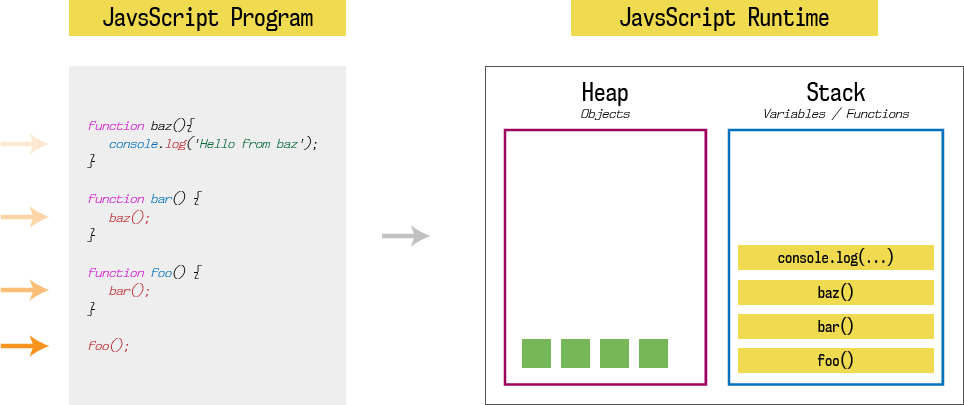
和其他编程语言一样,JavaScript运行时有一个栈(Stack)和一个堆(Heap)存储器。

上图来源于Fhinkel文章,关于栈和堆之间的差异讲得比较清晰. 举个例子:
在Java或者C#中, 值类型(primitives原始类型)存储在栈中,而引用类型(reference)则存储在堆中。C++规范没有规定栈和堆的内存分配,而是使用自动存储(automatic)期和动态存储(dynamic)期来作区分,局部变量是自动存储期,编译器会将它们存储在栈中。而动态分配的对象则通常保存在堆中。放在栈中的数据会在函数执行完毕后自动回收,而放在堆中的对象,如果没有释放就会造成内存泄露
本文不会深入解释Heap,你可以看这里. 在本文我们感兴趣的是栈,栈是一个LIFO(后进先出)的数据结构,用来保存程序当前的函数执行上下文, 换句话说,它表示的是当前程序执行的位置. 每次开始执行一个函数,就会将该函数推入栈中,当函数返回时从栈中弹出。 当栈为空时表示没有程序正在执行。所以栈常常也称为‘调用栈’。
function baz(){ |
因此, 当上面的程序加载进内存时,会开始执行第一个函数,即foo。 因此第一个栈元素就是foo(), 因为foo函数会调用bar函数,第二个栈元素就是bar(); 同理bar函数会调用baz,第三个栈元素就是baz(). 最后,baz调用console.log,最后一个栈元素就是console.log('Hello from baz')
栈会在函数执行完毕时(到达函数底部或者调用return)弹出。然后继续执行函数调用后续的语句:
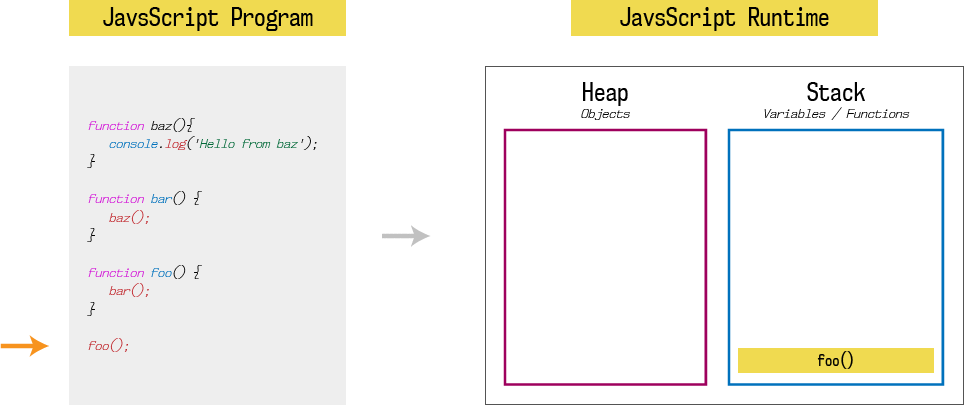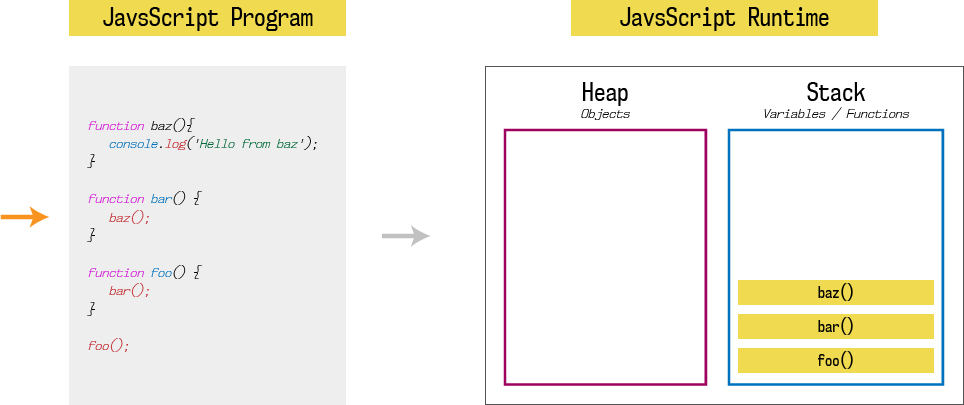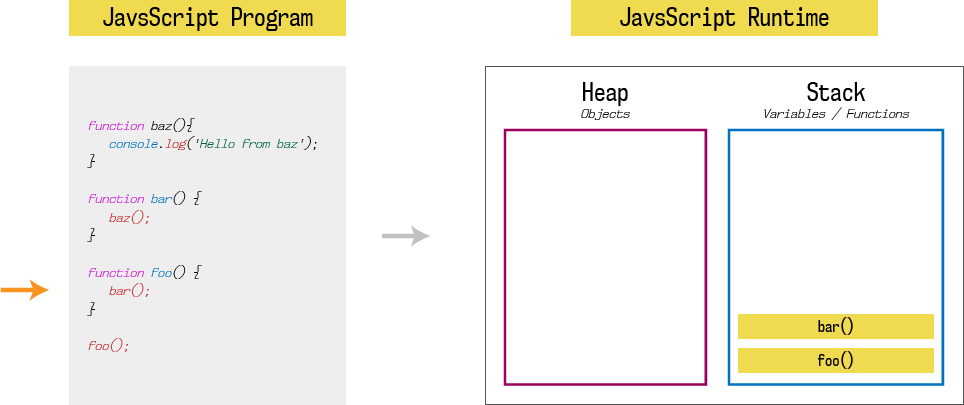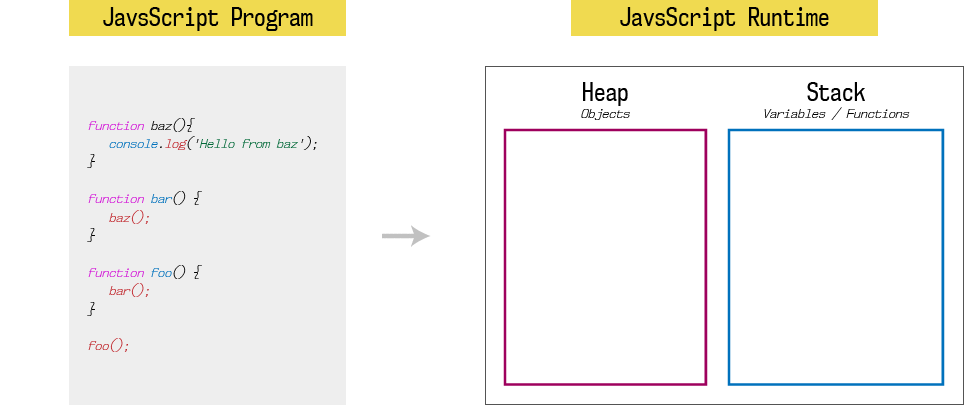
每个栈元素中,元素的状态也被称为栈帧(Stack Frame). 如果在函数调用抛出错误,JavaScript会输出栈跟踪记录(Stack trace),表示代码执行时的栈帧的快照。
function baz(){ |
上面的程序,我们在baz中抛出错误,JavaScript会打印出栈跟中记录,指出错误发生的地方和错误信息。

栈的大小不是无限的。例如Chrome就会限定栈的最大为16,000帧。所以无限递归会导致Chrome抛出Maximum Call Stack size exceeded:

事件循环与Web API
因为JavaScript是单线程的,所以它只有一个栈和堆。因此,如果其他程序想要执行一些东西,需要等待上一个程序执行完毕
对比其他语言,这可能是一个糟糕的设计,但是JavaScript的定位就是通用编程语言,而不是用于非常复杂的场景
考虑这样一个场景。假设浏览器发送一个HTTP请求到服务器,加载图片并展示到页面。浏览器会卡死等待请求完成吗?显然不会,这样用户体验太差了
浏览器通过JavaScript引擎来提供JavaScript运行环境。比如Chrome使用V8 引擎。但是浏览器内部可不只有JavaScript引擎。下面是浏览器的底层结构:
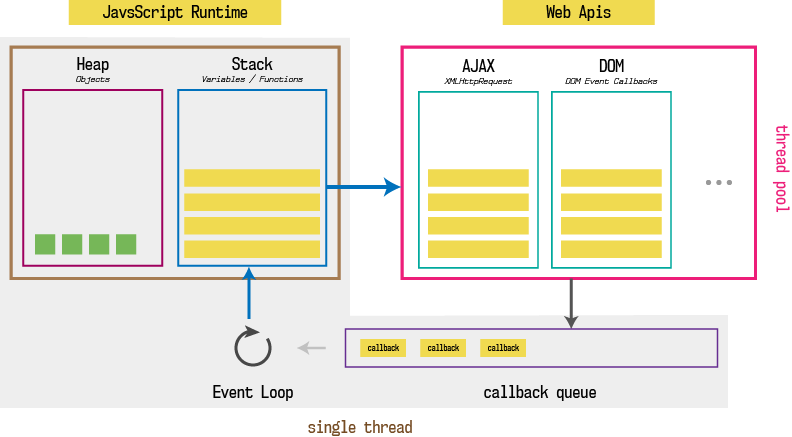
看起来很复杂,但是它也很好理解。JavaScript引擎需要和其他2个组件协作,即事件循环(EventLoop)和回调队列(CallbackQueue),回调队列也被称为消息队列或任务队列。
除了JavaScript引擎,浏览器还包含了许多不同的应用来做各种各样的事情,比如HTTP请求、DOM事件监听、通过setTimeout、setInterval延迟执行、缓存、数据存储等等。这些特性可以帮助我们创建丰富的Web应用。
想一下,如果浏览器只使用同一个JavaScript线程来处理上面这些特性,用户体验会有多糟糕。因为用户即使只是简单的滚动页面,背后是需要处理很多事情的, 单个Javascript线程压根忙不过来。因此浏览器会使用低级的语言,比如C++,来执行这些操作,并暴露简洁的JavaScript API给开发者。这些API统称为Web API。
这些Web API通常是异步的。这意味着,你可以命令这些API在’后台’(独立线程)去做一些事情,完成任务之后再通知Javascript运行时. 在此同时,Javascript引擎会继续执行剩下的JavaScript代码. 在命令这些API在后台做事情时,我们通常需要给它们提供一个回调。这个回调的职责就是在Web API完成任务后执行JavaScript代码。让我们将上述的所有东西整合起来理解一下:
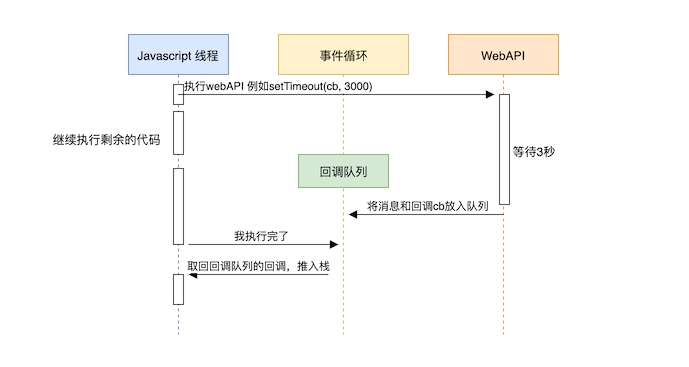
当你调用一个函数时,它会被推进栈中。如果这个函数中包含了Web API调用,JavaScript会代理Web API的调用, 通知Web API执行任务,接着继续执行下一行代码直到函数返回。一旦函数到达return语句或者函数底部,这个函数就会从调用栈中弹出来。
与此同时,如果Web API在后台完成了它的工作,且有一个回调和这个工作绑定,Web API会将消息结果和回调进行绑定,并推入到消息队列中(或者称为回调队列).
事件循环, 就像一个无限循环,它的唯一工作是检查回调队列,一旦回调队列中有待处理的任务,就将该回调推送到调用栈。不过因为Javascript是单线程的, 事件循环一次只能推送一个回调到调用栈,栈将会执行回调函数,一旦调用栈为空,事件循环才会将下一个回调函数推送到调用堆。
事件循环的伪代码大概如下:
while(true) { |
我们通过setTimeout Web API这个例子一步一步看看上述的一切是怎么运作的。setTimeout Web API主要用于延时执行一些操作,但是回调真正被执行, 需要等待当前程序执行完毕(即栈为空), 也就是说,setTimeout函数回调执行时间未必等于你指定的延时时间。setTimeout的语法如下:
setTimeout(callbackFunction, timeInMilliseconds); |
callbackFunction是一个回调函数,它将会在timeInMilliseconds之后执行. 我们修改上面的代码来调用setTimeout:
function printHello() { |
上面的代码延时调用了console.log. 栈还是会像之前一样,如foo() => bar() => baz(), 当baz开始执行并到达setTimeout时,Javascript会将回调函数传递给Web API,并且继续执行下一行。 因为这里没有下一行了,栈会弹出baz,接着弹出bar和foo。
在这期间,Web API正在进行3s等待,当时间到达时,它会将回调推进回调队列中。 因为这时候调用栈为空,事件循环会将这个回调推进栈中,并执行这个回调。
🎉🎉Philip Robers创建了一个神奇的在线工具Loupe,来可视化Javascript的底层运行。上面的实例可以查看这个链接🎉🎉
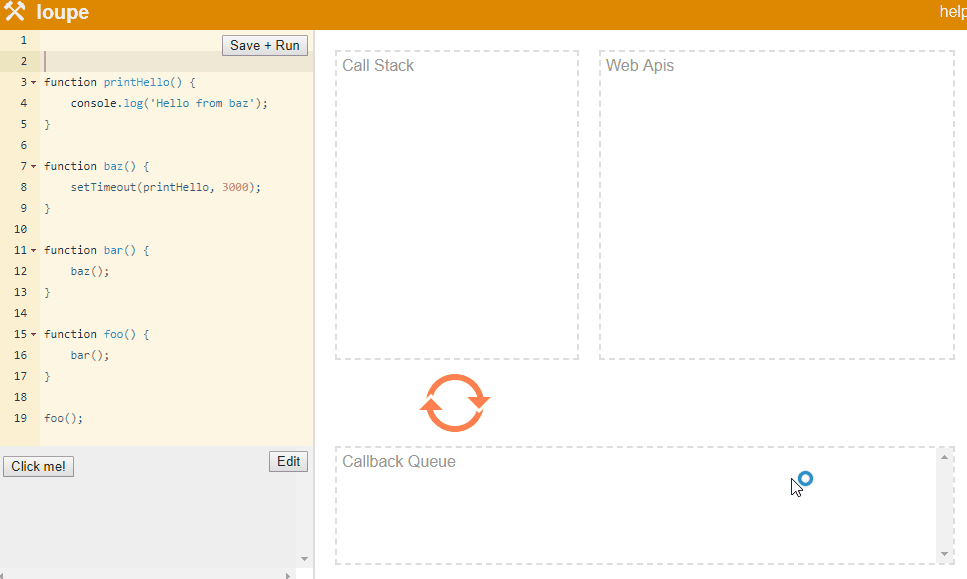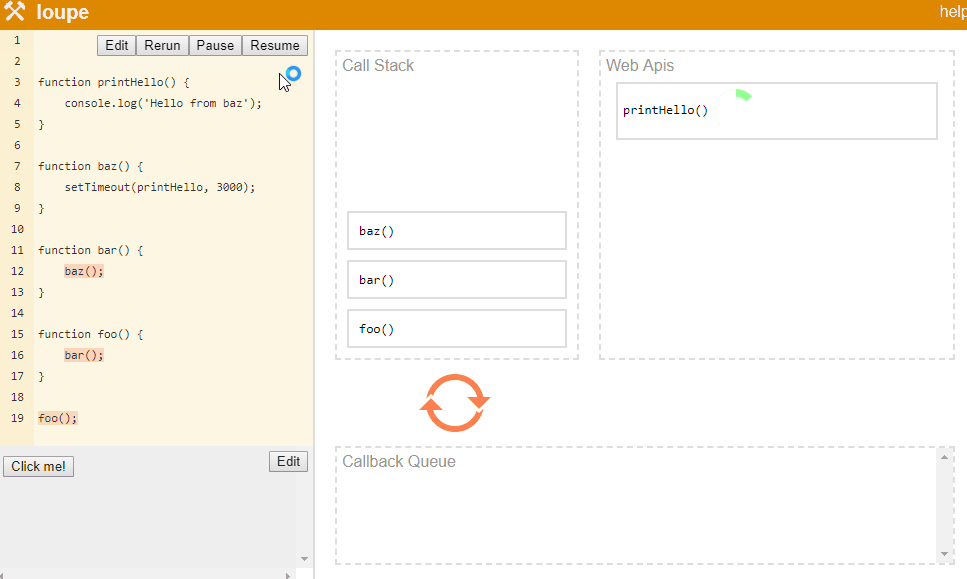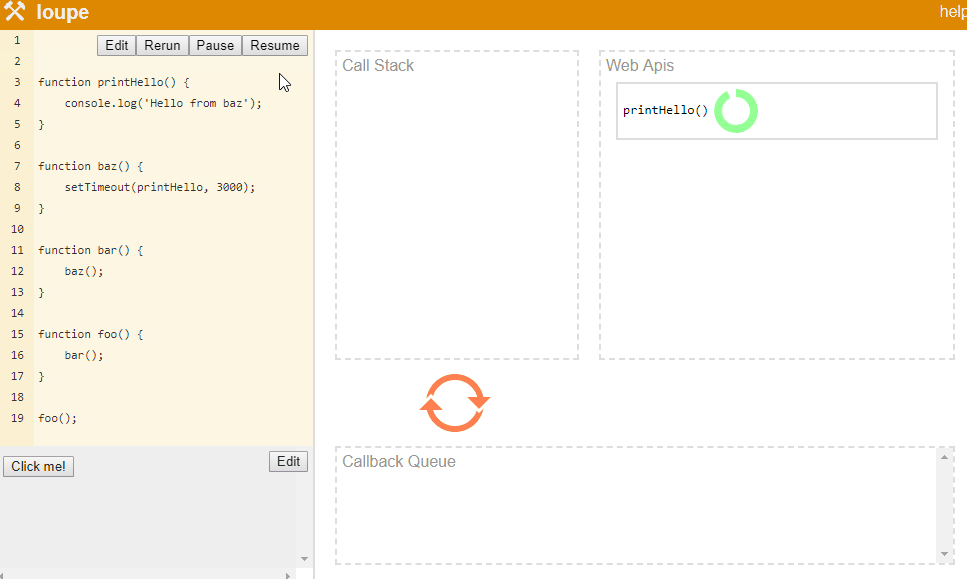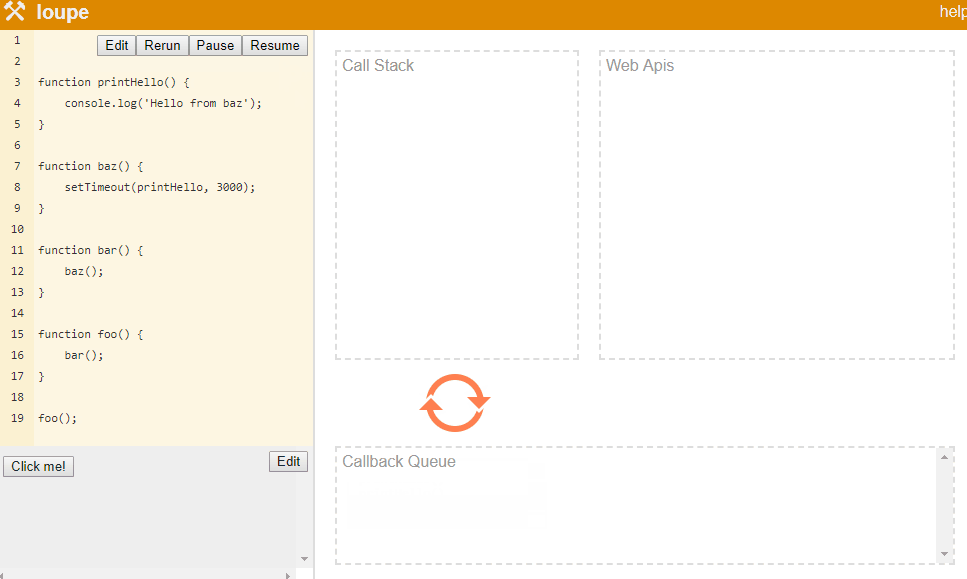
所以说我们Javascript是单线程的,但是很多Web API的执行是多线程的。也就是说Javascript的单线程指的是‘Javascript代码’的执行是单线程.
Node.js
通过Node.js我们可以做更多的事情, 而不仅限于浏览器的端。那么它是怎么运作的?
Node.js 和Chrome一样,同样使用Google的V8引擎来提供Javascript运行时. 它使用libuv(C++编写)来和V8的事件循环配合,扩展更多可以在后台执行的东西, 比如文件系统I/O, 网络I/O。Node的标准库API遵循了浏览器Web API的类似回调风格。
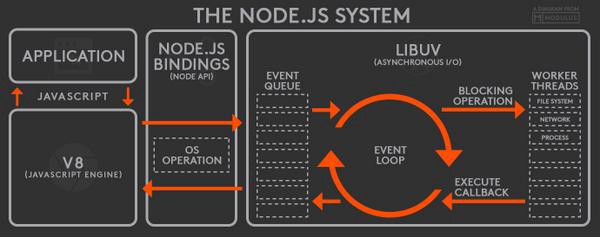
如果你比较了浏览器和node的结构图,你会发现两者非常相似。右侧的部分类似于Web API,同样包含事件队列(或者称为回调队列/消息队列)和事件循环。
V8、事件循环、事件队列都在单线程中运行,最右侧还有工作线程(Worker Thread)负责提供异步的I/O操作。这就是为什么说Node.js拥有非阻塞的、事件驱动的异步I/O架构。
上面的内容都来源于Philip Roberts30min的高光演讲(五年前)
本文完