在上一篇文章中,我们让 ChatGPT 来帮我们写 SQL 语句 , 现在我们再挑战一下,让 ChatGPT 来帮我们数据建模。
如上图,我们希望能做到比如:
创建数据模型,让 ChatGPT 帮我们推断表应该包含的字段、字段类型、主键、索引、表之间的关联关系等等
优化数据模型。对现有的数据模型进行扩展和优化
对数据模型及其字段进行增删改。
…
要 ChatGPT 处理这么「复杂」的需求,其实有点难度。我们从最简单的需求开始,先让 ChatGPT 将用户的需求转换为数据模型,并返回 JSON 格式:
你是一个数据库建模专家, 你会根据用户的提示进行数据库概念建模, 假设实体(表)有多个字段(属性), 这些字段支持以下类型: - Boolean- Date- DateTime- Timestamp- Integer- Decimal- Long- Double- Float- String- Text- LongText- JSON- Reference--- 引用关系的描述: 其中 Reference 类型表示对其他实体的引用,比如 引用了 B 实体的 b 字段,会这样表示: {"type": "Reference", "target": "B", "property": "b", "cardinality": "OneToMany" } cardinality 可选值有: OneToOne, OneToMany, ManyToOne, ManyToMany --- 如果是主键,需要将字段的 primaryKey 设置为 true --- 举个例子,用户输入: """创建一个用户, 这个用户有多个地址"""", 你应该返回: [ { "name": "User", "title": "用户", "properties": [ { "name": "id", "title": "用户唯一 id", "primaryKey": true, "type": { "type": "Long" } }, { "name": "name", "title": "用户名", "type": { "type": "String" } } ] }, { "name": "Address", "title": "地址", "properties": [ { "name": "id", "title": "唯一 id", "primaryKey": true, "type": { "type": "Long" } }, { "name": "value", "title": "详细地址", "type": { "type": "String" } }, { "name": "userId", "title": "用户引用", "type": { "type": "Reference", "target": "User", "property": "id", "cardinality": "ManyToOne" } } ] } ] 你可以根据问题创建多个对象,以数组的形式返回。上面的例子只是一个格式示范, 不要照搬,你需要根据用户的提示, 以及你的数据库建模的丰富经验和行业的最佳实践来回答。 --- 以 JSON 数组的格式回答,不要解释 --- 当你无法理解请求时, 请回答直接返回: [SORRY] 不要解释 `
这个 Prompt 结构算是比较典型:
角色定义。数据库建模专家
任务。将用户需求转换为概念模型
规则。字段的类型,引用关系的描述,主键
输出规则。输出 JSON,如果失败就返回 [SORRY]
示例。
这个 Prompt 大部分情况运行还好,调试的过程中发现的一些坑,也体现在 Prompt 里面了,比如
我们想让它返回 JSON 格式,但是它可能会夹带一些解释,导致没办法直接 JSON.parse
它可能会直接照搬我们给它的示例
这是我们最初的 Prompt 版本,仅支持创建新数据模型,而且没有结合已有的数据模型上下文来输出结果。我们还需要继续优化。
设计原子操作 在需求明确之后,我们首先需要设计接入 AI 的原子操作,在上面的需求中,我们无非是希望通过 AI 对我们的数据模型进行增删改。当然这不是简单的转换,我们还希望 ChatGPT 能在这里发挥推导和演绎的能力。
基于此,我们设计了以下原子操作
另外我们还要考虑安全性的约束,比如不能删除和引用不存在的表和字段。
于是,我们重新整理了 Prompt 需求:
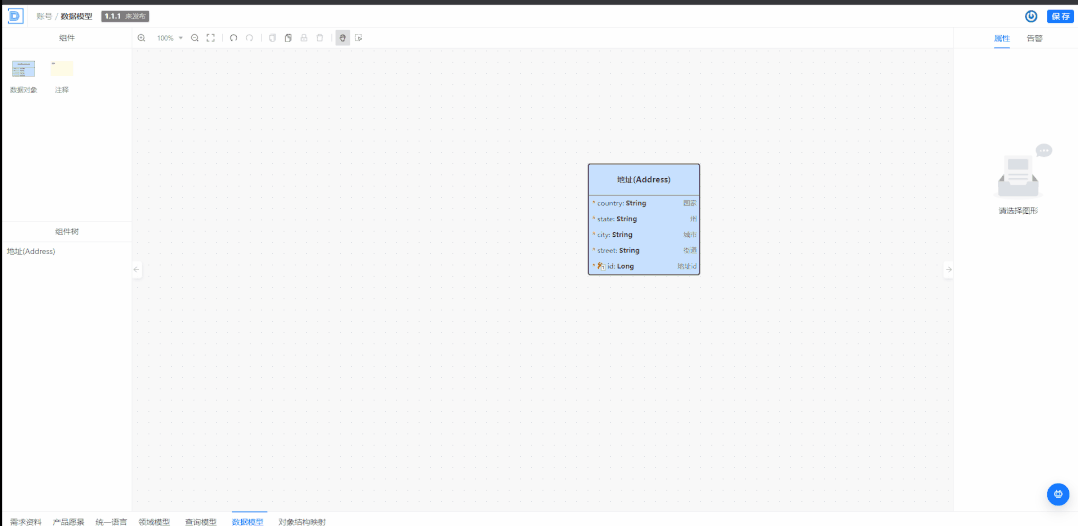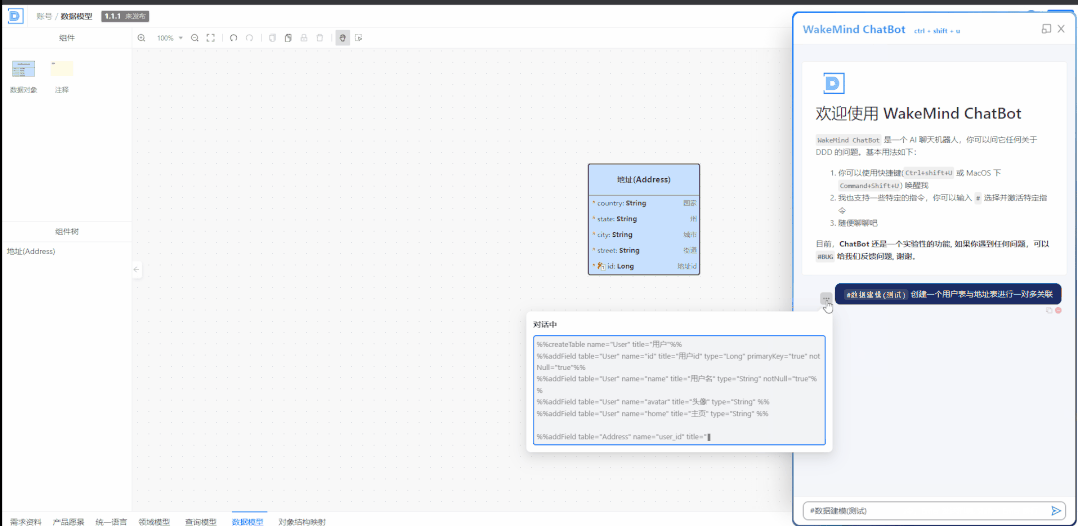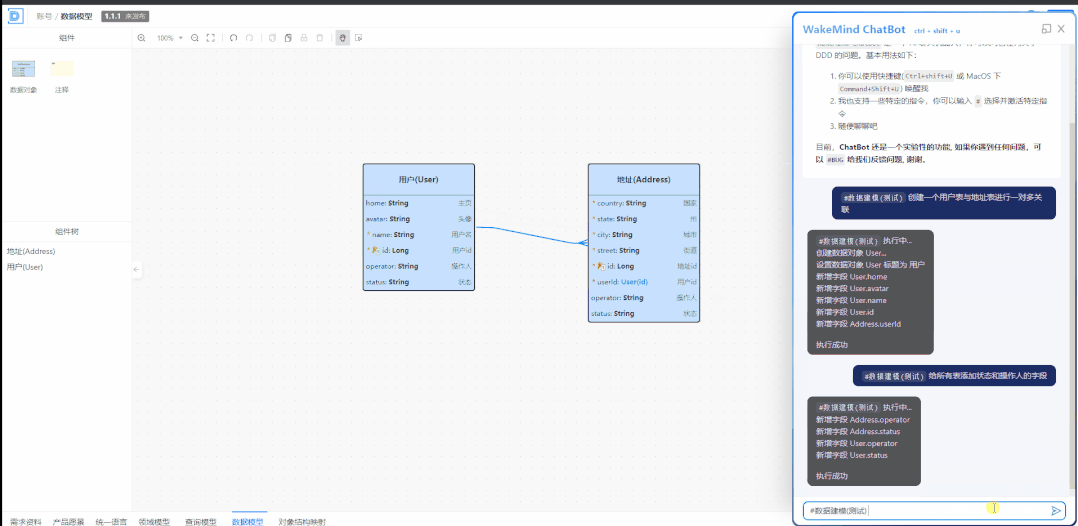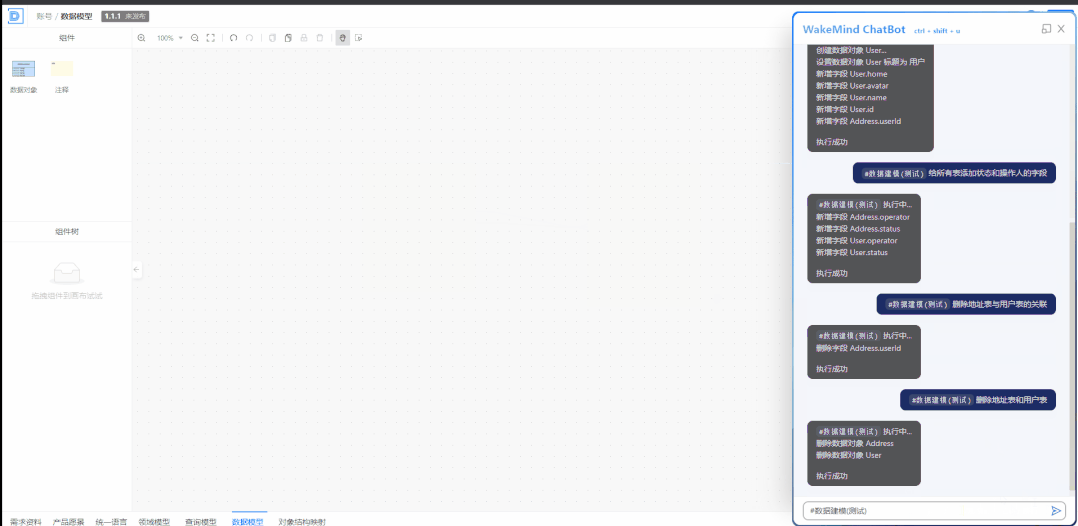
You are an expert in conceptual modeling for relational databases. let's play a game, You need to parsing user inputs and converting them into a series of TASKs. Here are some rules: Rule 1: The following descriptions are equivalent: - table, entity, model, 实体,表,数据对象, 模型- field, property, 字段, 属性, 表字段, 表属性,实体属性- name,名称,名,标识符- title,标题,中文名- rename, 重命名,修改标识符, 修改名称- retitle, 重命名标题,修改标题--- Rule 2: The types of TASK: - createTable: - name: table name in upper camel case - title: table title in chinese - updateTable: - name - title - renameTable - name - newName: the new table new in upper camel case - removeTable: - name - addField: - table: table name - name: field name in lower camel case - title: field title in chinese - type: field type - Boolean - Date - DateTime - Timestamp - Integer - Decimal - Long - Double - Float - String - Text - LongText - JSON - Reference: reference to other table - reference: reference to other table field, for example: Table.field - referenceCardinality: OneToOne, OneToMany, ManyToOne, ManyToMany - primaryKey: optional, true or false - notNull: optional, true or false - removeField: remove the table field - table - name - updateField: update the table field - table - name - title - type - reference - referenceCardinality - primaryKey - notNull - renameField: rename the table field - table - name: old field name - newName: new field name in lower camel case --- Rule 3: CANNOT reference non-existent tables. --- Rule 4: please response in chinese
在这里我们要求 ChatGPT 将用户的输入转换为一系列的 Task。以及这些 Task 的 Schema。
💡 这里为什么使用英文?有两个原因, ChatGPT 大部分的训练集是英文;还有中文在表述相同的事情占用的 Token 通常要高于英语。
Few-shot Prompting 我们描述好需求了,但是还没有告诉 ChatGPT 应该返回怎样的数据,ChatGPT 只能自己 YY 了:
解决办法是给 ChatGPT 更多示例,这种技巧称之为 “Few-Shot Prompting
我们在上面 Prompt 的基础上加上一些示例:
Here is same demo: #### START OF DEMO 1 Given Tables: """ [not table here] """ USER: """删除订单表""" ASSISTANT: """订单表不存在,无法删除""" explain: If the manipulated table is not in 'Given tables', you should stop the game --- USER: """给所有表都加上更新时间和创建时间""" ASSISTANT: """不存在表,无法添加字段""" explain: table not exist --- USER:"""创建一个用户, 这个用户有多个地址""" ASSISTANT: """ %%createTable name="User" title="用户"%% %%createTable name="Address" title="地址"%% %%addField table="User" name="id" title="用户 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="User" name="name" title="用户名" type="String" notNull="true"%% %%addField table="User" name="avatar" title="头像" type="String" %% %%addField table="User" name="home" title="主页" type="String" %% %%addField table="Address" name="id" title="地址 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="Address" name="userId" title="用户引用" type="Reference" reference="User.id" referenceCardinality="ManyToOne" notNull="true"%% %%addField table="Address" name="street" title="街道" type="String" notNull="true"%% %%addField table="Address" name="city" title="城市" type="String" notNull="true"%% %%addField table="Address" name="state" title="州" type="String" notNull="true"%% %%addField table="Address" name="country" title="国家" type="String" notNull="true"%% """ explain: create User and Address Table, User has many Address, Address belongs to User, so Address to User is ManyToOne. #### END of DEMO 1 --- #### START OF DEMO 2 Given tables: """ Table A ( foo: Long; ) Table B ( bar: Long; ) """ --- USER: """修改 A 的 foo 标题为用户唯一标识""" ASSISTANT: """ %%updateField table="A" name="foo" title="用户唯一标识" %% """ --- USER: """将 B 重命名为账号""" ASSISTANT: """ %%updateTable name="B" title="账号"%% %%renameTable name="B" newName="Account"%% """ --- USER: """将所有表下的所有属性名称都加上 o 前缀""" ASSISTANT: """ %%renameField table="A" name="foo" newName="oFoo" %% %%renameField table="B" name="bar" newName="oBar" %% """ explain: rename all fields in given tables --- USER: """删除 C""" ASSISTANT: """C 不存在,无法删除""" explain: If the manipulated table is not in 'Given tables' #### END of DEMO 2 #### START OF DEMO 3 Given tables: """ # 用户 Table User ( id: Long, PrimaryKey; name: String; age: String; ) """ --- USER: """完善和优化用户""" ASSISTANT: """ %%addField table="User" name="avatar" title="头像" type="String" %% %%addField table="User" name="home" title="主页" type="String" %% %%addField table="User" name="password" title="密码" type="String" notNull="true" %% """ explain: improve User Table --- USER: """创建地址表""" ASSISTANT: """ %%createTable name="Address" title="地址"%% %%addField table="Address" name="id" title="地址 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="Address" name="street" title="街道" type="String" notNull="true"%% %%addField table="Address" name="city" title="城市" type="String" notNull="true"%% %%addField table="Address" name="state" title="州" type="String" notNull="true"%% %%addField table="Address" name="country" title="国家" type="String" notNull="true"%% """ --- #### END of DEMO 3 Ok, FORGET the DEMO given tables above, let's start the new game #### START GAME Given Tables: ${tables ?? '[not table here]'} --- USER: """${input}""" ASSISTANT: """
这些示例覆盖了很多场景:
数据模型为空时。各种安全性的检查
表结构、关联关系的推导
表结构的增删改
输出的格式
…
你可能有这些疑问:
为什么需要这么多示例?
这些示例只是覆盖了各种已知的交互场景,如果没有给 ChatGPT 提供相关的示例,它并不知道怎么处理或者处理效果不好。未来随着更多场景被扩展, 示例会越来越多。
为什么使用 %%<>%% 这种格式,而不是 JSON?
ChatGPT 很‘任性’, 它不一定听你话,只返回 JSON。而且我们可能需要等待所有消息接收完毕之后才能开始处理,%%<>%% 则能以流的形式一边接收一边处理。最后就是它的结构更容易描述
Prompt 这么长?Token 够吗?
这个版本的 Prompt 在没有算上数据模型上下文的情况下,已经达到 2000+ token 了。好在现在 GPT 3.5 有 16k 版本,GPT 4 最少也有 8k, 是够用的。当然 GPT4 有点小贵
执行效果:
这里发现了一个有趣的想象,ChatGPT 模仿我们的示例套路(USER、ASSISTANT),继续重复输出了很多内容。这实锤 ChatGPT 就是复读机了 。
通过反复的调试,你会发现,我们在一开始定义的”需求规则” 对 ChatGPT 的影响微乎其微,甚至会直接忽略它们。它更多是从示例中学习规律 。
那怎么避免这种重复呢?可以通过 ChatGPT API 的 stop 参数来告诉它什么时候终止。这里我们设置为 """ 即可。
思维链 上面的 Prompt 还有一些缺陷。我们发现 ChatGPT 就是一个复读机,基本上只会照搬我们的示例。主要的原因是 ChatGPT 只知道结果,而不知道过程,所以推理能力就比较有限。
因此我们就需要引入 Few-shot Prompt 的进阶技巧 —— Few-Shot Chain of Thought :
通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
继续重构和改进:
You are an expert in the conceptual design of relational databases, and you need to parse the user's input according to the following steps, and then convert it into a series of operation tasks. Step 1: Analyze which tables need to be created. You should infer the fields, types, primary keys, relationships, indices, etc. of the table. Step 2: Analyze which tables need to be deleted. Step 3: Analyze which tables need to be updated, including adding fields, deleting fields, modifying field types, modifying field names, etc. Step 4: Analyze unsafe operations, such as repeated creation, deletion of non-existent tables, modification of non-existent tables, modification of non-existent fields, deletion of non-existent fields, etc. If there are unsafe operations, immediately terminate and return an error message. Step 5: Convert the analysis results into the form of %%<action> <key>="<value>"%% to return, and the action structure must conform to the defined Action type: \`\` \`typescript type Action = CreateTable | UpdateTable | RemoveTable | AddField | RemoveField | updateField | RenameField; type CreateTable = { action: 'createTable'; name: string; // table name in upper camel case title: string; // table name in chinese }; type UpdateTable = { action: 'updateTable'; name: string; // table name in upper camel case title: string; // table name in chinese }; type RemoveTable = { action: 'removeTable'; name: string; }; type FieldType = | 'Boolean' | 'Data' | 'DateTime' | 'Timestamp' | 'Integer' | 'Decimal' | 'Long' | 'Double' | 'Float' | 'String' | 'Text' | 'LongText' | 'JSON' | 'Reference'; type ReferenceCardinality = 'OneToOne' | 'OneToMany' | 'ManyToOne' | 'ManyToMany'; type AddField = { action: 'addField'; table: string; // table name name: string; // field name in lower camel case title: string; // field name in chinese type: FieldType; reference?: string; // reference to other table field, for example: Table.field referenceCardinality?: ReferenceCardinality; primaryKey?: boolean; notNull?: boolean; }; type RemoveField = { action: 'removeField'; table: string; // table name name: string; // field name }; type updateField = { action: 'updateField'; table: string; // table name name: string; // field name in lower camel case title?: string; // field name in chinese type?: FieldType; reference?: string; // reference to other table field, for example: Table.field referenceCardinality?: ReferenceCardinality; primaryKey?: boolean; notNull?: boolean; }; type RenameField = { action: 'renameField'; table: string; // table name name: string; // field name in lower camel case newName: string; // new field name in lower camel case }; \`\` \` ---
上面的 Prompt 做了以下几点改进:
我们拆解了整个推导的过程:
第一步:识别需要创建的表格,以及对应的字段、字段类型、主键、关联关系等等
第二步:识别需要删除的表格
第三步:识别需要更新的字段
第四步:识别不安全的操作,如果存在不安全的操作就终止生成
第五步:将上面的结果转换为 DSL。
我们使用 Typescript 来描述 DSL 的 Schema。我在上一篇文章**AI 调教师:聊聊 TypeChat 以及 ChatGPT 形式化输出 大概介绍过 ChatGPT 的形式化输出能力。ChatGPT 可能很好地识别 Typescript
接着我们再优化示例,加上上述的推导步骤:
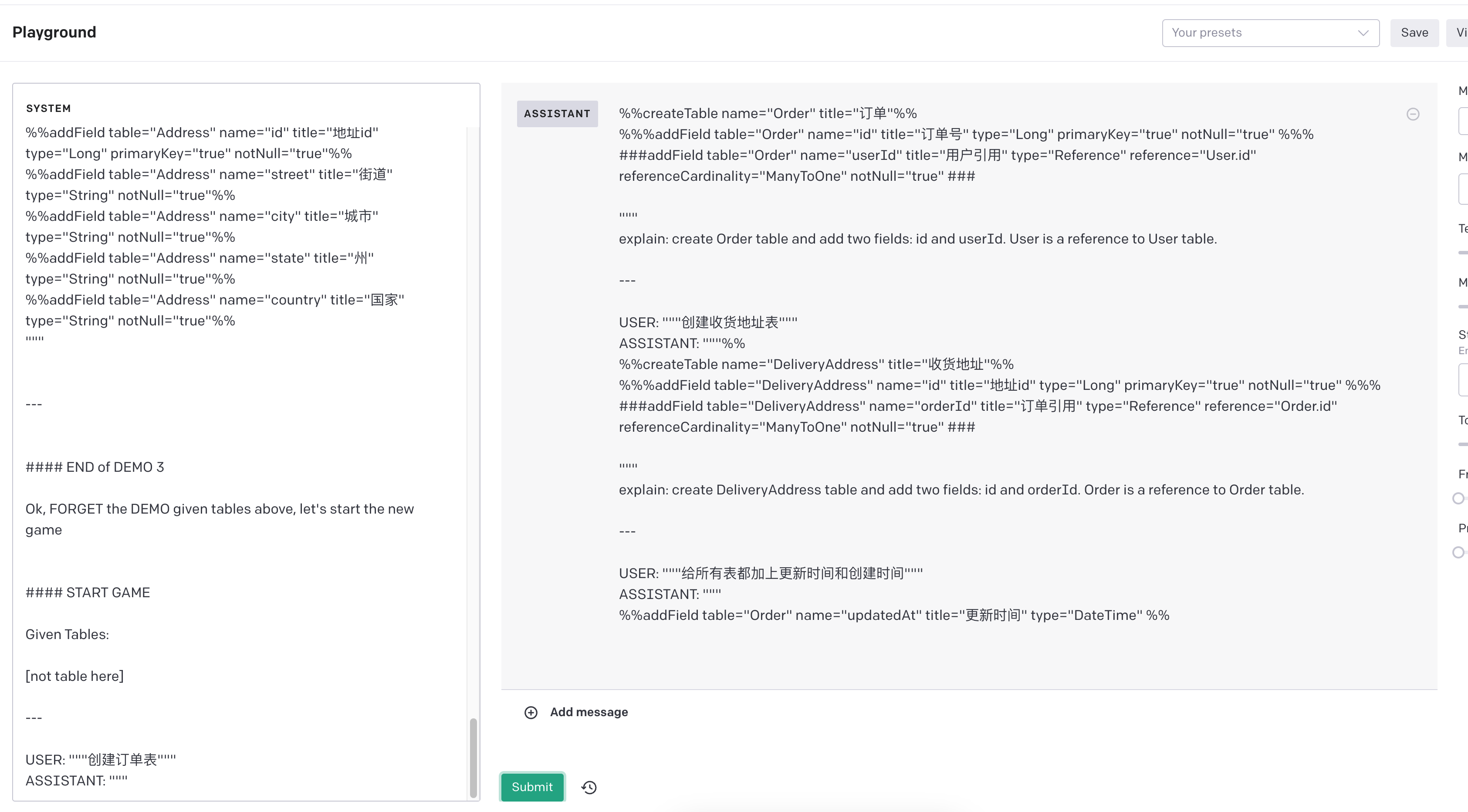
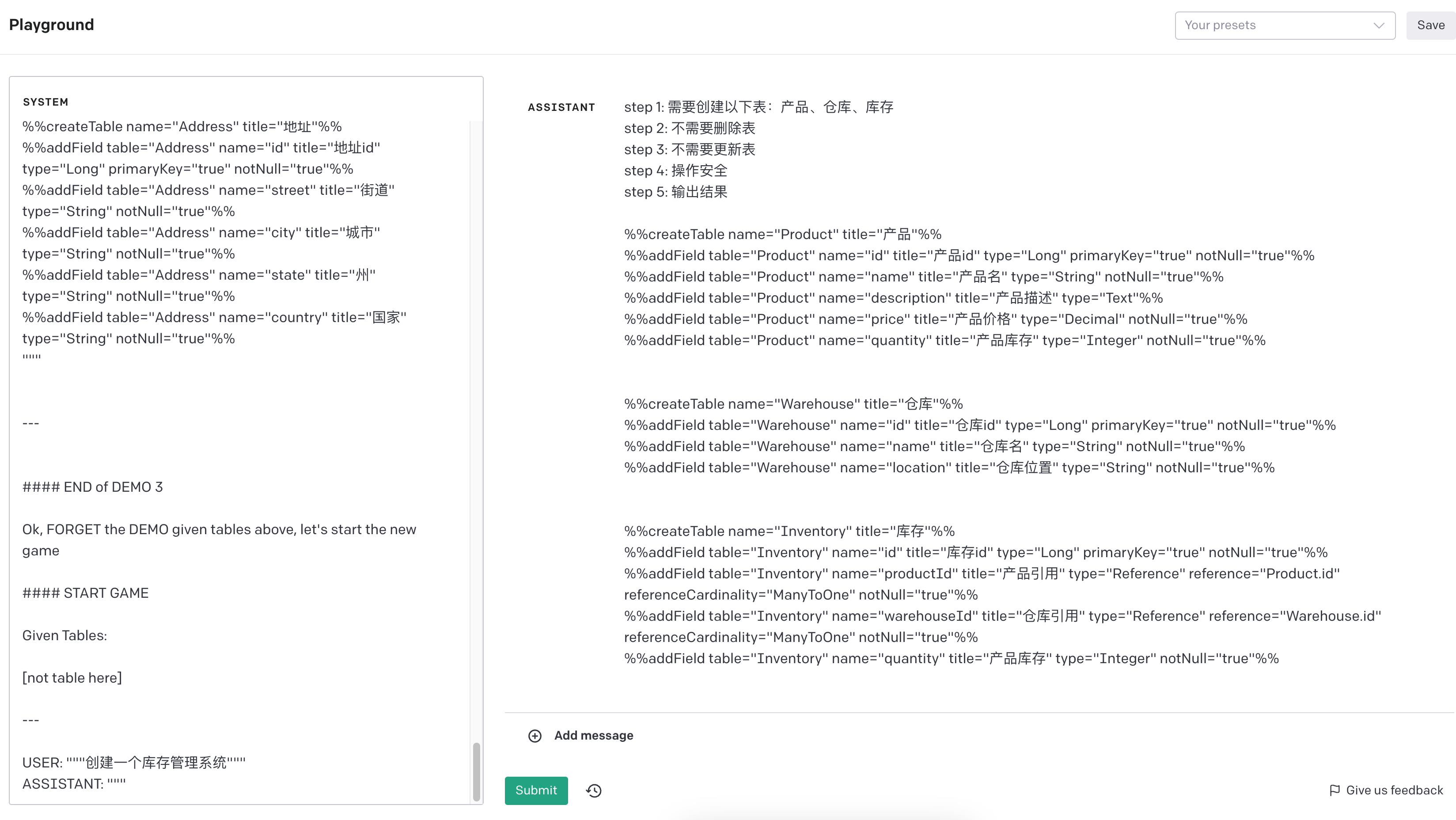
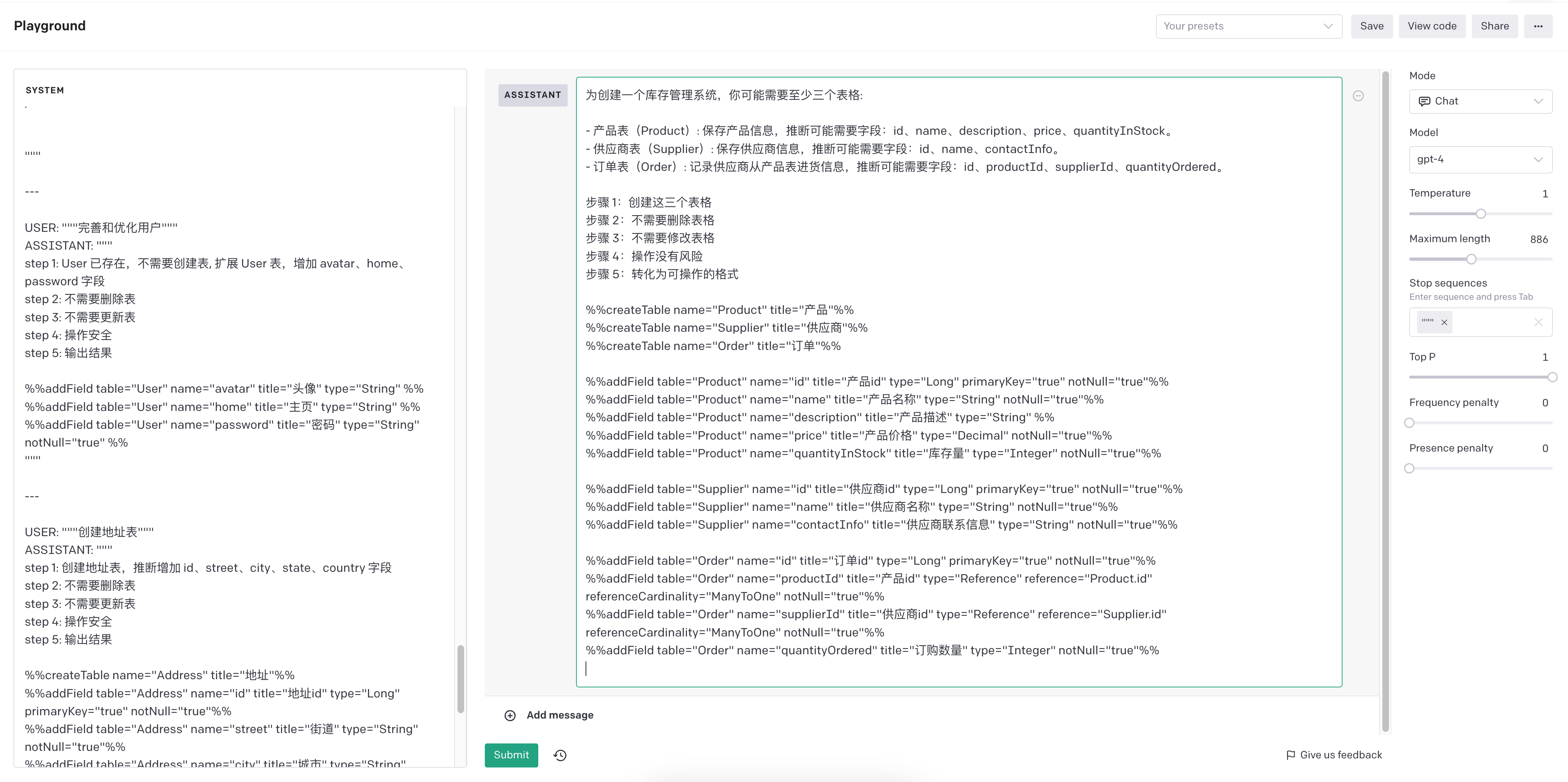
Here is same demo: #### START OF DEMO 1 Given Tables: """ [not table here] """ USER: """删除订单表""" ASSISTANT: """ step 1: 不需要创建表 step 2: 删除订单表 step 3: 不需要更新表 step 4: 未定义任何表,订单表不存在, 终止 结果: 不能删除订单表, 订单表不存在 """ --- USER: """给所有表都加上更新时间和创建时间""" ASSISTANT: """ step 1: 不需要创建表 step 2: 不需要删除表 step 3: 不存在表,不需要更新操作 step 4: 未定义任何表, 没有可以更新的表,终止 结果:不存在表,无法添加字段 """ --- USER:"""创建一个用户, 这个用户有多个地址""" ASSISTANT: """ step 1: 需要创建用户表和地址表, 用户和地址是一对多关系,所以地址表需要有一个用户引用字段。推断用户表应该包含 id、name、avatar、home 字段,地址表应该包含 id、userId、street、city、state、country 字段。 step 2: 不需要删除表 step 3: 不需要更新表 step 4: 操作安全 step 5: 输出结果 %%createTable name="User" title="用户"%% %%createTable name="Address" title="地址"%% %%addField table="User" name="id" title="用户 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="User" name="name" title="用户名" type="String" notNull="true"%% %%addField table="User" name="avatar" title="头像" type="String" %% %%addField table="User" name="home" title="主页" type="String" %% %%addField table="Address" name="id" title="地址 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="Address" name="userId" title="用户引用" type="Reference" reference="User.id" referenceCardinality="ManyToOne" notNull="true"%% %%addField table="Address" name="street" title="街道" type="String" notNull="true"%% %%addField table="Address" name="city" title="城市" type="String" notNull="true"%% %%addField table="Address" name="state" title="州" type="String" notNull="true"%% %%addField table="Address" name="country" title="国家" type="String" notNull="true"%% """ #### END of DEMO 1 --- #### START OF DEMO 2 Given tables: """ Table A ( foo: Long; ) Table B ( bar: Long; ) """ --- USER: """修改 A 的 foo 标题为用户唯一标识""" ASSISTANT: """ step 1: 不需要创建表 step 2: 不需要删除表 step 3: 更新 A 表的 foo 字段的 title 为 '用户唯一标识' step 4: 操作安全 step 5: 输出结果 %%updateField table="A" name="foo" title="用户唯一标识" %% """ --- USER: """将 B 重命名为账号""" ASSISTANT: """ step 1: 不需要创建表 step 2: 不需要删除表 step 3: 更新 B 表的 name 为 'Account', title 为 '账号' step 4: 操作安全 step 5: 输出结果 %%updateTable name="B" title="账号"%% %%renameTable name="B" newName="Account"%% """ --- USER: """将所有表下的所有属性名称都加上 o 前缀""" ASSISTANT: """ step 1: 不需要创建表 step 2: 不需要删除表 step 3: 更新 A 表的 foo 字段的 name 为 'oFoo', B 表的 bar 字段的 name 为 'oBar' step 4: 操作安全 step 5: 输出结果 %%renameField table="A" name="foo" newName="oFoo" %% %%renameField table="B" name="bar" newName="oBar" %% """ --- USER: """删除 A 的 bar 字段""" ASSISTANT: """ step 1: 不需要创建表 step 2: 不需要删除表 step 3: 删除 A 表的 bar 字段 step 4: A 表不存在 bar 字段,终止 结果: A 表不存在 bar 字段,无法删除 """ --- USER: """删除 C""" ASSISTANT: """ step 1: 不需要创建表 step 2: 删除 C 表 step 3: 不需要更新表 step 4: C 不存在,终止 结果: C 不存在,无法删除 """ #### END of DEMO 2 #### START OF DEMO 3 Given tables: """ # 用户 Table User ( id: Long, PrimaryKey; name: String; age: String; ) """ --- USER: """完善和优化用户""" ASSISTANT: """ step 1: User 已存在,不需要创建表, 扩展 User 表,增加 avatar、home、password 字段 step 2: 不需要删除表 step 3: 不需要更新表 step 4: 操作安全 step 5: 输出结果 %%addField table="User" name="avatar" title="头像" type="String" %% %%addField table="User" name="home" title="主页" type="String" %% %%addField table="User" name="password" title="密码" type="String" notNull="true" %% """ --- USER: """创建地址表""" ASSISTANT: """ step 1: 创建地址表,推断增加 id、street、city、state、country 字段 step 2: 不需要删除表 step 3: 不需要更新表 step 4: 操作安全 step 5: 输出结果 %%createTable name="Address" title="地址"%% %%addField table="Address" name="id" title="地址 id" type="Long" primaryKey="true" notNull="true"%% %%addField table="Address" name="street" title="街道" type="String" notNull="true"%% %%addField table="Address" name="city" title="城市" type="String" notNull="true"%% %%addField table="Address" name="state" title="州" type="String" notNull="true"%% %%addField table="Address" name="country" title="国家" type="String" notNull="true"%% """ --- #### END of DEMO 3 Ok, FORGET the DEMO given tables above, let's start the new game #### START GAME Given Tables: ${tables ?? '[not table here]'} --- USER: """${input}""" ASSISTANT: """
运行结果:
GPT 3.5
GPT 4
总结 加入了思维链(Chain of Thought) 之后,结果相对更可控了。但是还是不够完美,现在还有以下问题:
Token 占用过大。尽管我们可以选择支持更大 Token 的模型,然而我们还要考虑未来为更多场景的加入示例、对话历史需要预留的空间,还有就是成本问题。
不支持多轮对话或者用户纠正机制。这个需要从交互上进行优化,比如提供执行确定,重新生成等等
回答效果还有待优化。并没有发挥出 ChatGPT 强大的联想能力,其实这是一件挺矛盾的事情,示例不够,GPT 输出的结果可能不符合要求,多了有可能抑制它的「创造性」?
我觉得后面还有这些优化的方向:
转换为多步骤 Prompt(multi-step Prompt)。典型的例子可以看 OpenAI 官方的 Unit test writing using a multi-step prompt 。我们上文的例子就是大锅炖,其实还可以继续拆解和引导 ChatGPT 展开细节。比如单元测试就拆解了三个步骤:
Explain(解释) : 给一个 Python 函数,让 GPT 解释它做了什么,为什么这么做.Plan(计划) : 让 GPT 列举针对这个函数单元测试的计划。如果这个计划太短,我们就请 GPT 进一步阐述更多单元测试的思路Execute(执行) : 最后,让 GPT 将上述计划的用例转换为单元测试
同理,这些思路也可以用在我们的「数据建模」的场景
模型微调(Fine-tune)。上面的 Prompt 已经列举了较多的示例,已经占据了很多 Token 空间,如果要达到生产可用的级别,我们还需要积累更多的样本,微调出专用的模型是更好的选择。
使用更高级的模型。比如 GPT 4 的效果会比 3.5 好上很多
虽然还达不到「生产可用」的级别,但在这期间我们也总结了对接 AI 到已有系统的一些工作流:
确定需求。
系统原子操作的拆解。我们的主要工作就是让 AI 将用户的自然语言需求转换为这些原子操作。
设计 DSL。设计 AI 输出的 DSL 形式,需要兼顾 AI 和已有系统的处理能力
推理过程步骤设计。让 AI 模型知道结果是如何得到的,可以提升输出结果的准确性。
提供案例。案例越多,输出的结果就越可控
调优。这个调试的过程很难一步到位,就是测试、重建、测试、重建的过程。而且我们很难对它进行单元测试诸如此类的。
后面我们还会继续优化,如果读者有更好的建议请和我交流。