使用 Docker 实现前端应用的标准化构建、部署和运行
Why Docker?
Docker 容器化技术是当今最重要的基础设施之一,或者说它已经成为服务程序 的标准化运行环境。
先不谈它相比传统的虚拟化技术有多少优势,站在软件工程角度,笔者认为,Docker 有两个重要的意义:
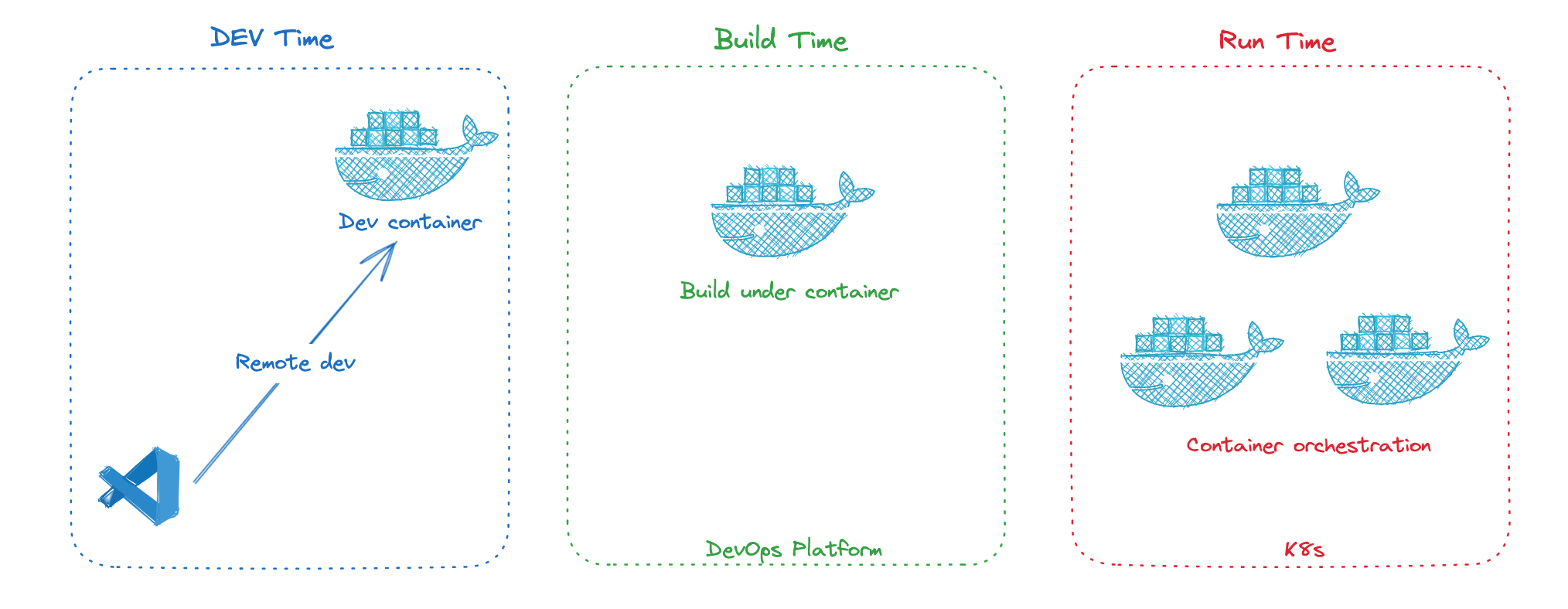
一)提供一致性的运行环境。让我们的程序在一致性的环境中运行:不管是开发环境、测试环境、还是生产环境;不管是开发时、构建时、还是运行时。
比如开发时可以使用 Docker Dev Environments, 可以配合 VsCode Remote 开发,从而实现跳槽时或者换设备,可以快速 Setup 自己的开发环境。有兴趣的可以看看掘友写的 Docker化一个前端基础开发环境:简洁高效的选择
构建时,现在 CI/CD 平台都是基于 Docker 来提供多样化的构建环境需求。
运行时,‘巨轮’ K8S 已经是云时代的重要基础设施。
二)标准化的服务程序封装技术。
在没有容器之前,使用不同编程语言或框架编写的程序,部署和运行的方式千差万别。比如 Java 会生成 jar 包或者war 包,运行环境需要预装指定版本的 JDK…
而现在,容器镜像成为了标准的服务程序封装技术。镜像中包含了程序以及程序对运行环境的依赖。

不管前后端应用都可以使用镜像的形式进行分发和流通。这应该就是 Docker Logo,那条鲸鱼驮着货运箱的解释吧:就像我们平时下载、传递 Zip 文件一样, 镜像是云时代’通用货币’,可以在研发的不同环节、区域中流通。
这种标准化的打包格式、轻量化的运行时,不仅给开发者和运维带来便利, 也催生了强大的容器管理工具比如 K8S, K8S 现在已经是容器和集群管理的标准。
那 Docker 之于前端意义是啥?
Docker 对前端的意义也很重大。 实际上,Docker 的世界里,并不区分什么前端、后端,没有人说只适合后端、不适合前端 … 在运维的眼里更是如此
为了照顾那些不太懂 Docker 的开发者,本文会循序渐进、由浅入深地讲解。如果你需要 Docker 入门教程,推荐你看看 Docker —— 从入门到实践
主要分成三个部分:
- 标准化的 CI/CD。讲讲怎么基于 Docker 来构建前端应用,这里提出了一个重要的观点:就是基于 Dockerfile 来实现 ‘跨 CI/CD’ 的任务执行,我们可以在 Dockerfile 中执行各种任务,包括环境初始化、单元测试、构建等等
- 标准化部署和运行。怎么部署基于 Docker 的前端应用,包括静态资源、NodeJS 程序、微前端。
- 一些高级的话题。讲讲容器化后的前端应用怎么实现 ’一份基准代码,多份部署‘、灰度发布、蓝绿发布等高级发布需求。
标准化CI/CD
市面上有很多 CI/CD 产品,比如 GitLab、Github Action、Jenkins、Zadig… 它们的构建配置、脚本语法差异都挺大,基本上是不能共用的。
比如我们公司前不久引入了 Zadig,原本基于 Jenkinks 的构建配置几乎需要重新适配。
有没有跨‘平台’的方式?于是,我开始探索将前端 CI/CD 的流程完全集成到 Docker 镜像构建中去。
从简单的单元测试开始
我们先从简单的任务开始。先来写一个简单的单元测试:
FROM node:20-slim |
⁉️ corepack? NodeJS 的包管理碎片化越来越验证了,以前我们区分 npm、yarn、pnpm, 现在还要继续分裂版本,pnpm v7、pnpm v8…
NodeJS 官方推出的 Corepack 应该可以救你一命
别忘了 .dockerignore
node_modules |
⁉️ 为什么不能遗漏
.dockerignore呢?
构建运行:
$ docker build . --progress=plain |
二次运行的结果:
#1 [internal] load build definition from Dockerfile.for_test |
Docker 镜像是多层存储的, 每一层是在前一层的基础上进行的修改。换句话说, Dockerfile 文件中的每条指令(Instruction)都是在构建新的一层。
Docker 使用了缓存来加速镜像构建,所以上面执行结果可以看出只要上一层和当前层的输入没有变动,那么执行结果就会被缓存下来。
现在你可以随便更动 src/* 或者 package.json , 再执行构建,会发现,从 COPY 指令那里重新开始执行了:
# ... |
也就是,又从 0 开始进行 pnpm install …
缓存处理
前端构建会深度依赖缓存来加速,比如 node_modules、Webpack 的模块缓存、vite 的 prebundle、Typescript 的 tsBuildInfoFile …
上面从零开始 pnpm install 显然是无法接受的。每次都是从头开始,构建的过程会变得很慢。有什么解决办法呢?
解决办法 1)利用 Docker 分层缓存
pnpm 依赖的安装,其实只需要 package.json、pnpm-lock.yaml 等文件就够了,那我们是不是可以把 COPY 拆分从两步?采用动静分离策略,分离 package.json 和源代码的变更。毕竟 package.json 的变更频率要低得多:
FROM node:20-slim |
解决办法 2) RUN 挂载缓存
方案1 还是有很多缺陷,比如 package.json 只要变动一个字节,都会导致 pnpm 重新安装。能不能在运行 build 的时候挂载缓存目录进去?把 node_modules 或者 pnpm store 缓存下来?
Docker build 确实支持挂载(BuildKit, 需要 Docker 18.09+)。以下是缓存 pnpm 的示例(来自官方文档):
FROM node:20-slim |
💡你也可以通过设置
DOCKER_BUILDKIT=1环境变量来启用BuildKit
RUN —mount 参数可以指定要挂载的目录,对应的缓存会存储在宿主机器中。这样就解决了 Docker 构建过程的外部缓存问题。
同理其他的缓存,比如 vite、Webpack,也是通过 —mount 挂载。一个 RUN 支持指定多个 —mount
⚠️ 因为采用挂载形式,这种跨设备会导致
pnpm回退到拷贝模式(pnpm store → node_modules),而不是链接模式,所以安装性能会有所损耗。
如果是 npm 通常需要缓存
~/.npm目录
多阶段构建
假设我们要在原有单元测试的基础上,加入编译任务。并且要求两个命令支持独立执行,比如在代码 commit 到远程仓库时只执行单元测试,发布时才执行单元测试 + 编译。
第一种解决办法就是创建两个 Dockerfile, 这个方案的缺点就是指令重复(比如 pnpm 安装依赖)。另一个缺点就是如果任务之间有依赖或文件交互,那么整合起来也会比较麻烦。
更好的办法就是多阶段构建(Multi-Stage)。Docker 允许将多个构建步骤整合在一个 Dockerfile 文件中,这个构建步骤之间可以存在依赖关系,也可以进行文件传递,还可以更好地利用缓存。
# 🔴 阶段 1,安装依赖 |
通过 FROM * as NAME 的形式创建一个阶段。FROM 可以指定依赖的其他步骤。
现在我们运行:
$ docker build . |
默认会执行最后一个阶段。即 build。
如果我们只想跑 test,可以通过 —target 参数指定:
$ docker build --target=build . |
我们再来看一个典型的复杂例子,Nextjs 程序构建:
FROM node:19-alpine AS base |
多阶段构建的另一个好处是隐藏构建的细节: 比如上游构建的过程中传递的一些敏感信息、隐藏源代码等。
在上面的 Next.js 例子中, 最终构建的是 runner, 它从 builder 中拷贝编译的结果,对最终的镜像使用者来说,是查看不到 builder 的构建细节和内容的。
构建参数
程序在构建时可能会有一些微调变量,比如调整 Webpack PublicPath、编译产物的目标平台、调试开关等等。
在 DockerFile 下可以通过 ARG 指令来声明构建参数 :
# 声明构建参数,支持默认值 |
ARG 和 ENV 的效果一样,都是设置环境变量。不同的是,ARG 所设置是构建时的环境变量,在将来容器运行时是不会存在这些环境变量的。
⚠️ 注意,尽量不要在
ARG放置敏感信息,因为docker history可以看到构建的过程
通过 docker build --build-arg Key=[Value] 设置构建参数:
$ docker build --build-arg BABEL_ENV=test . |
怎么支持更复杂的构建需求?
Dockerfile 中不建议放置复杂的逻辑,而且它语法支持也很有限。如果有复杂的构建需求,更应该通过 Shell 脚本或者 Node 程序来实现。
集成到 CI/CD 平台
上文,我们探索了使用 Docker 来实现‘跨平台’(CI/CD) 的构建任务。看起来还不错,应该能够满足我们的需求。
通常这些平台对 Docker 镜像构建的支持都是开箱即用的, 如果使用 Dockerfile 方案,我们可以免去一些额外的声明,比如构建依赖的软件包、缓存配置、构建脚本等等。
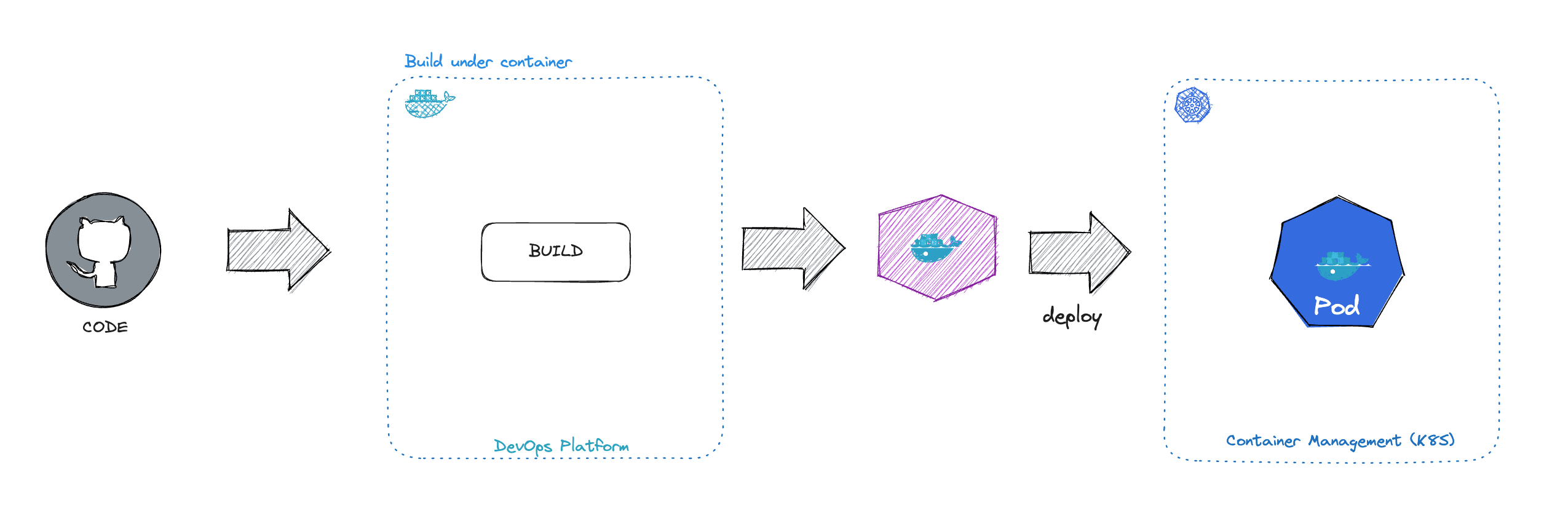
现在只需要关注 Dockerfile 构建, 下图以 Zadig 为例。在 Zadig 中,我们只需要告诉 Dockerfile 在哪,其余的工作(比如镜像 tag、镜像发布)都不需要操心:
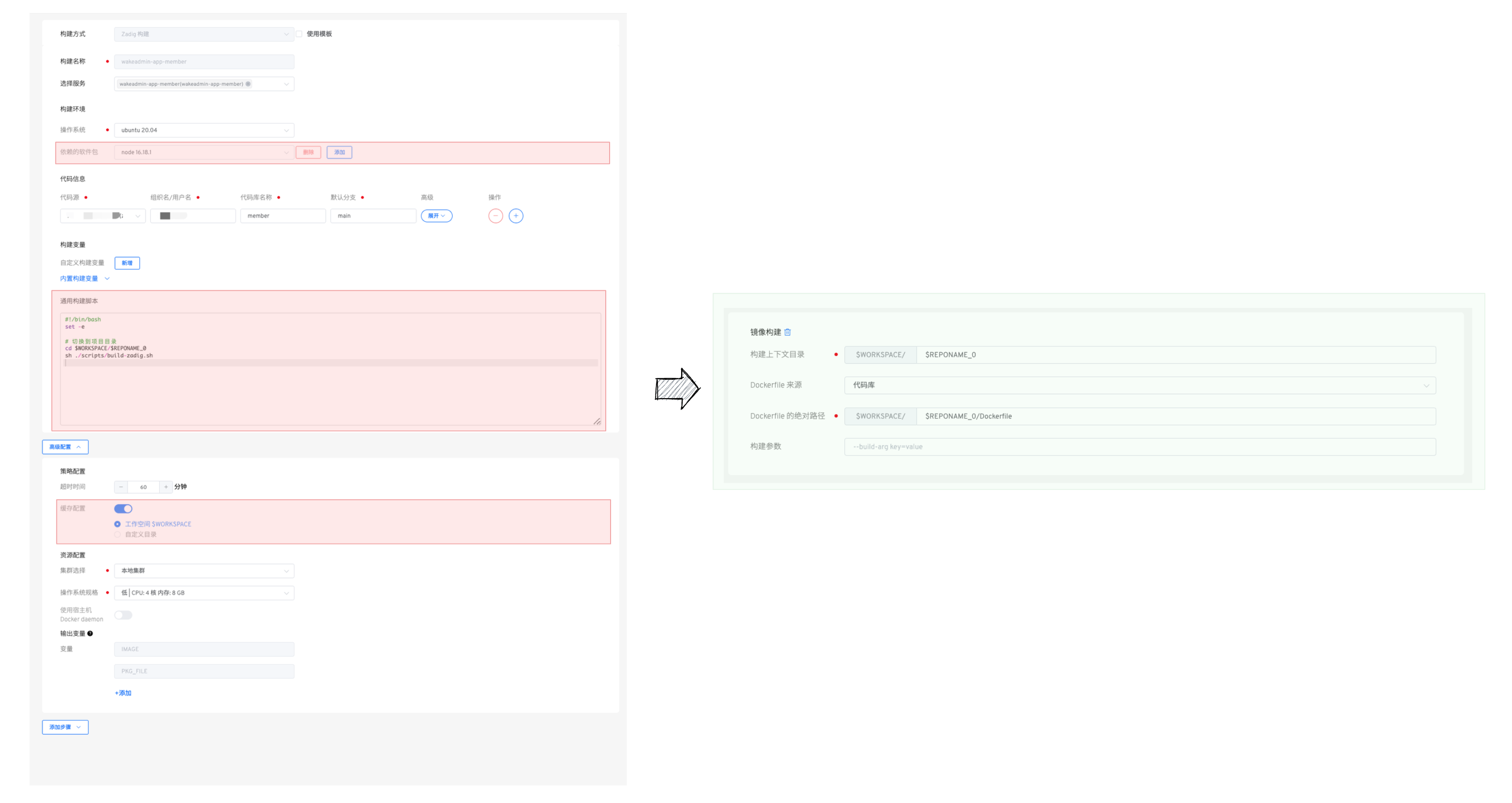
接入其他构建平台也是类似的,我们只需要学习对应平台如何构建镜像就行。
标准化部署和运行
上一节, 讲到将 Docker 作为‘跨平台’的任务执行环境。下一步就是发布、部署、运行。注意接下内容可能需要你对 K8S 有基本的了解。
镜像发布就不用展开说了,就和 npm 发布一样简单。本节的重点在于讨论,前端‘应用’在容器环境如何对外服务。
目前比较主流的前端应用可以分为三类:
- 纯静态资源。
- NodeJS 程序。包括 NodeJS 的纯后端服务、还有 NextJS、NuxtJS 这里 SSR 服务
- 微前端。主要指以基座为核心的中心化的微前端方案, 比如
qiankun。这类程序需要基座和子应用相互搭配才能对外服务。
纯静态资源
估计 80% 以上的前端应用都是纯静态的。
笔者尝试过多种部署的方式。在我们将前端应用容器化的初期, 有过这样一种中间的演进形态:
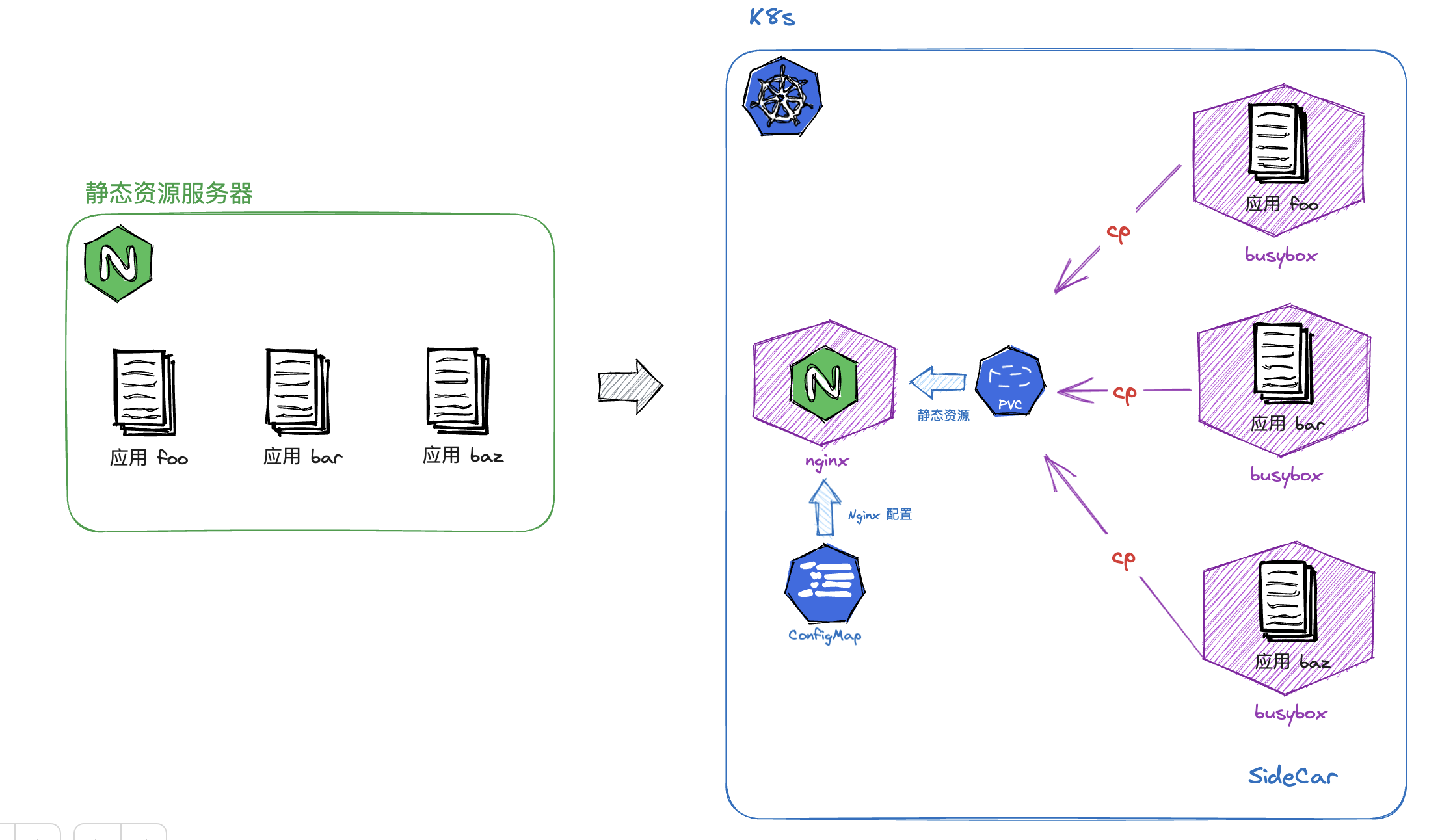
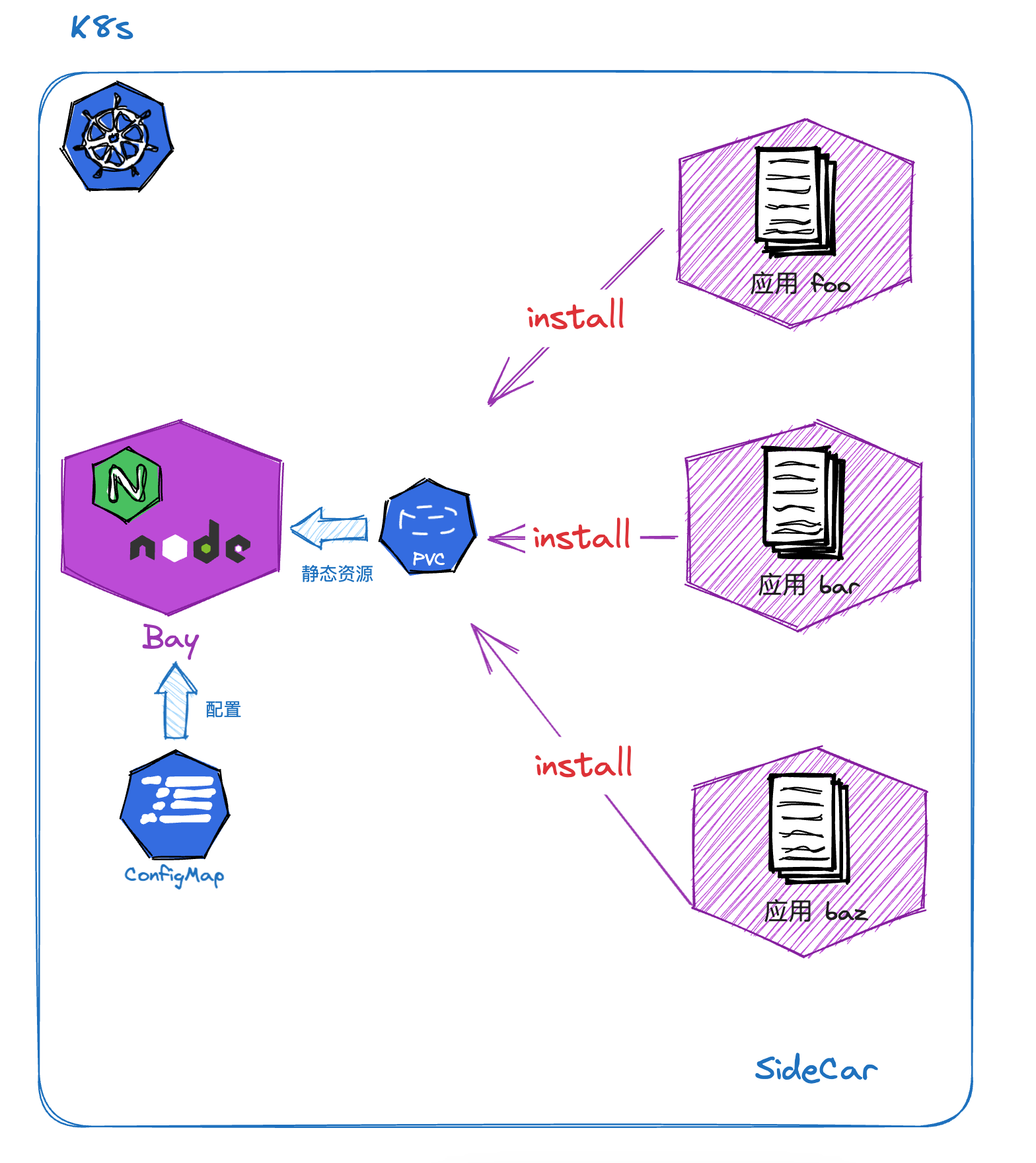
在改造之前我们所有的前端静态资源都堆在一个静态资源服务器中(上图左侧),所有人都有部署权限、所有人都能改 Nginx 配置、目录混乱。部署方式也是各显神通,有 Jenkins 自动部署、有 FTP/rsync 手动上传… 就是一个极其原始的状态。
在容器化改造的初期,运维把静态资源服务器转换成为了 Nginx 容器,而原本 Nginx 的配置通过配置映射(Config Map)来挂载到容器内部。
前端应用也做了非常简单的改造, 就是简单把静态资源 COPY 到镜像中:
FROM busybox:latest |
运行时,前端应用以 Nginx 容器的 Sidecar 形式存在,在启动时向共享的 PVC (数据卷)拷贝静态资源。
更理想的情况是每个前端应用能够独立对外服务, 对镜像的使用者来说,他应该是开箱即用的、自包含、透明的。
所以我们对部分比较独立的应用进行了重构:
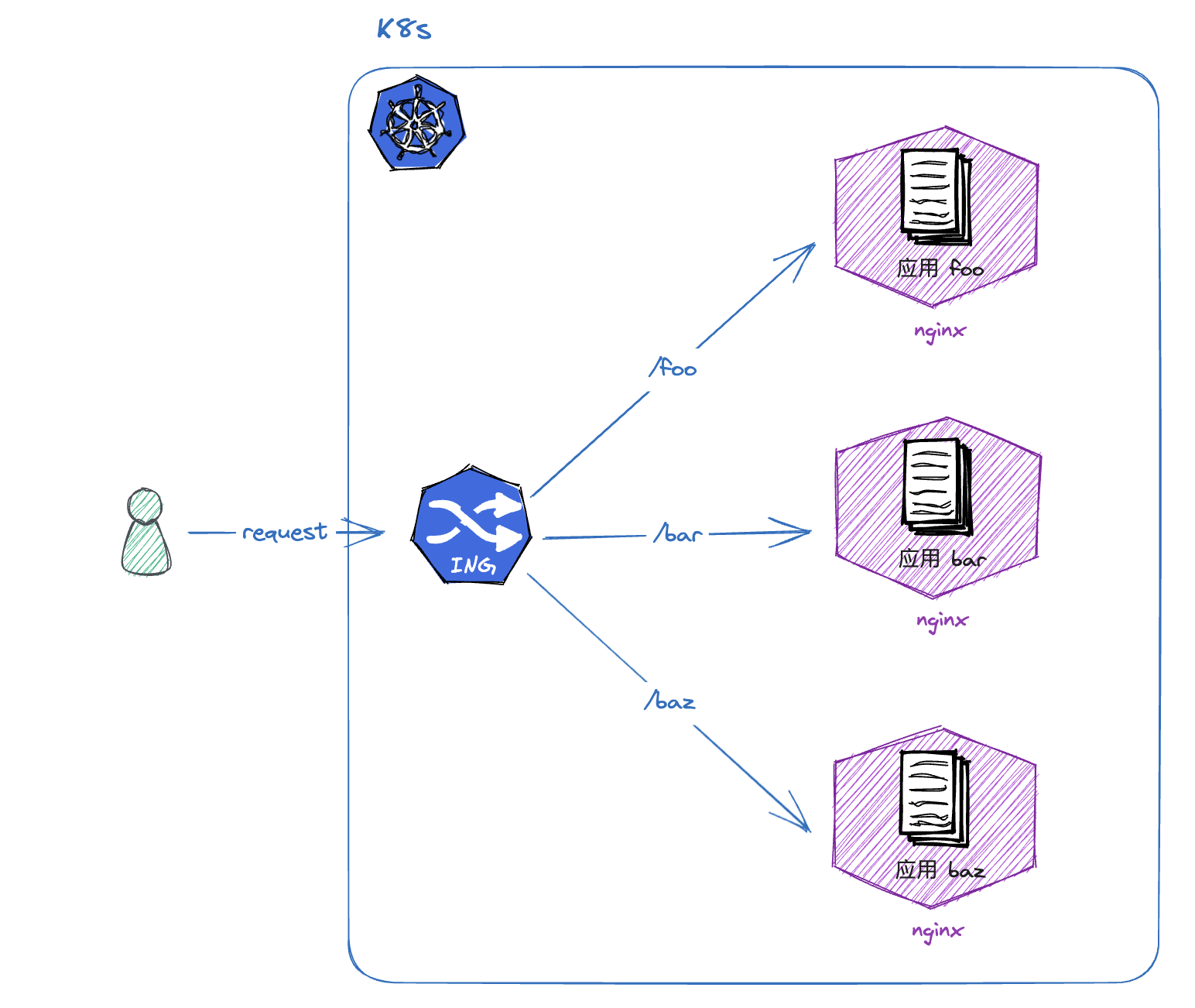
如上图, 前端应用基于 nginx 运行,流量会通过 Ingress 来分发到不同的应用,分发的方式通常有域名、请求路径等等。
这也进一步简化了运维的工作,运维只需要前端后两个镜像就可以将一套系统部署起来。
我们稍微改造一下上文的 Dockerfile 来支持 nginx 部署:
# 🔴 阶段 1,安装依赖 |
NodeJS 程序
这个和普通后端服务没什么区别,狭义上不属于前端的范畴,没有太多可以讲的,可以参考上文的 Next.js 示例。
微前端
我在微前端的落地和治理实战 中简单介绍过:
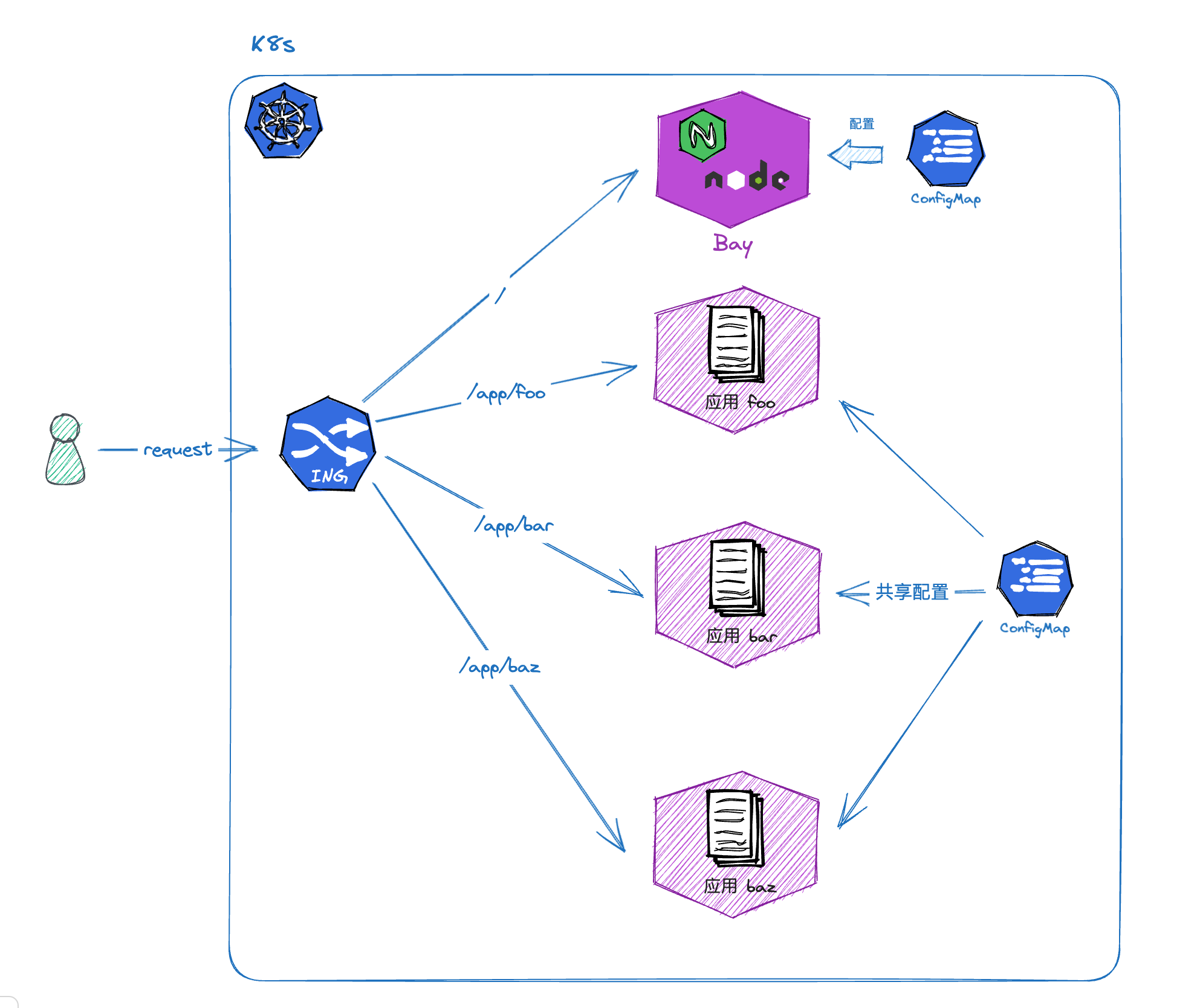
我们公司目前采用的是上图的 Sidecar 模式。每个子应用都是一个 Sidecar,启动时将自己‘注册’到基座中,由基座统一对外服务。
好处:基座可以统一管理所有子应用。比如可以实现‘子应用发现’、动态配置替换之类的工作
坏处:依赖 PVC 共享存储。我们也有遇到部分客户环境不支持共享 PVC 的。
对于不支持共享 PVC 的场景,我们也会进行回退:
让每个子应用独立对外服务,每个子应用都有自己的前缀, Ingress 根据前缀来分发流量。
好处就是子应用可以自己管理自己,升级和流量控制会更加灵活。缺点就是基座无法感知到这些子应用的存在,需要手动配置这些子应用的信息。
如果要更进一步,可以将基座定义为类似后端“注册中心”, 子应用主动向基座注册,有点后端微服务的味道了。如果真需要复杂到这一步,也没有必要自己造轮子,复用后端的技术栈不是更香?
除此之外,还有很多手段,比如基座提供发布服务,子应用调用基座发布服务,将自己的应用信息、静态资源提交给基座。
不是银弹
上面我们介绍了基于 Docker 容器的前端应用部署的各种方式和场景。但这并不是银弹!前端也不一定非得就要容器化。
很多大厂都有自己成熟的发布、部署流程和系统平台,他们需要应付各种复杂的情况, 比如大流量、CDN 同步、熔断降级、灰度发布、蓝绿发布,回滚… 那本文讲到的各种‘朴素’的技巧,就是一种雕虫小技
那它对我们为什么有用?
我们主要做 ToB 业务,容器化的方案可以应付私有化交付、私有化部署需求。开发和运维会面对各种千奇百怪的运行环境、公有云、私有云。但大部分甲方都会提供基础的 K8S 环境,容器化对我们来说就是一个最简单且高效的方案。
另外,依托于 K8S 这类强大容器管理平台,大部分问题都有解决方案,何必造轮子呢?
一些高级话题
一份基准代码,多份部署
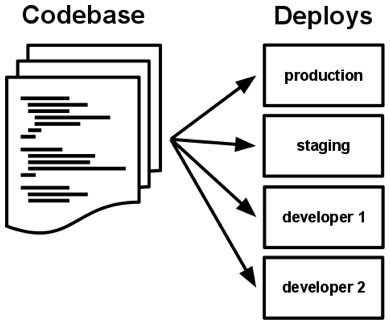
12-factors 里有一个原则:一份基准代码,多份部署。如果放在容器这个上下文中,就是一个镜像应该能够在不同的环境部署,而不需要任何修改。
这对我们做 ToB 的也很重要,如果我们为一个客户做一次私有化部署,就要将所有的应用重新构建一遍,这显然无法接受。
对于后端服务来说,很容易做到,要么通过环境变量,要么就从配置中心动态拉取。
而对于前端来说,静态资源的各种 URL (比如 CDN 链接) 和配置可能在构建时就固定下来了。而且我们的代码不运行在服务端,因此也不能通过环境变量来动态配置。
当然,也有解决办法:
- 使用 SSR。理论上可以解决,但是现代前端框架不是纯动态的,也会有一个编译的过程
- 模板替换。可以参考 微前端的落地和治理实战 ,运行容器。
- 还有古老的 SSI(ServerSideInclude) 技术。
下面以 Nginx SSI + Vite 为例, 演示一下 SSI:
vite 配置:
import { defineConfig } from 'vite' |
<!--# echo var='public_url' --> 是 SSI 的指令语法。这里使用 Vite 实验性的 renderBuiltUrl 来配置(因为直接使用 base 会有问题)。
Dockerfile:
FROM nginx:stable-alpine |
nginx 配置文件中无法愉快地引用环境变量,所以曲线救国, 使用 envsubst 来替换 nginx.conf 中的环境变量占位符。
Nginx 配置:
# ... 省略 |
自己试试看吧!
如何做灰度发布、蓝绿发布…?
在 K8S 环境,有挺多简单的手段可以实现灰度(金丝雀发布)发布、蓝绿发布这些功能,比如:
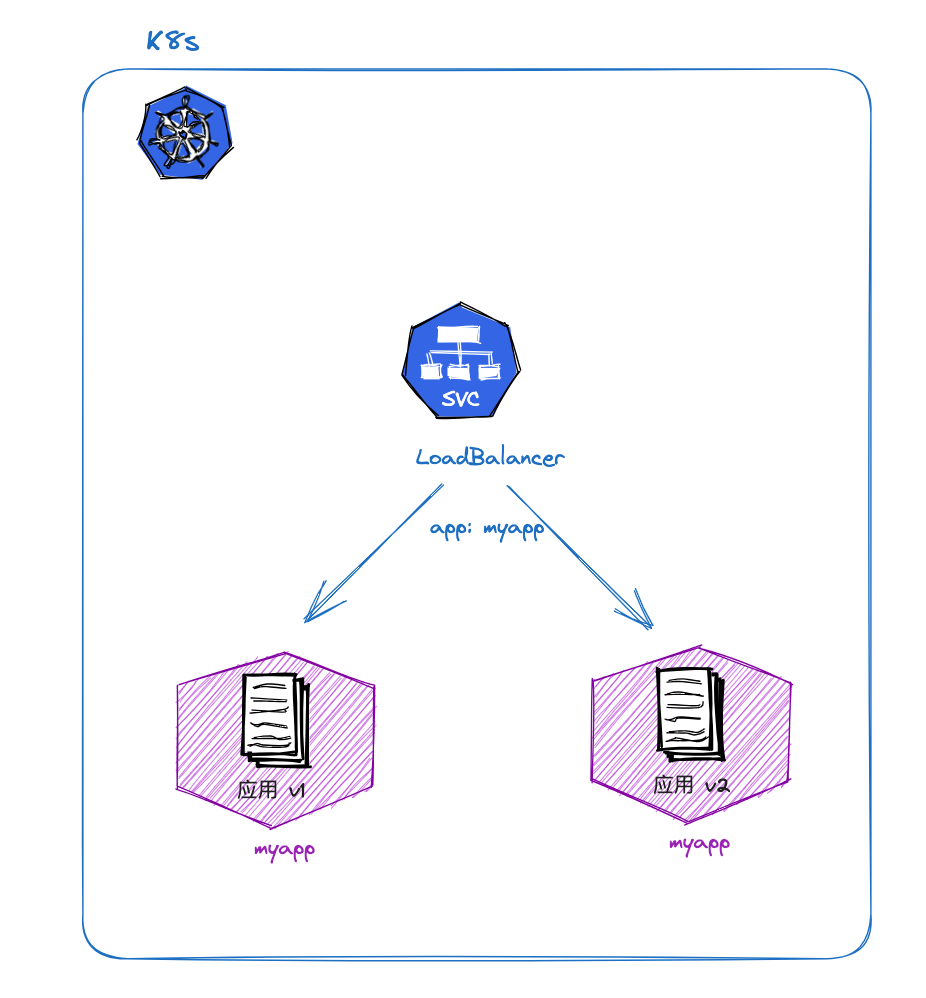
通过 Service。一个 Service 实际上可以映射到多个 Deployment。通过调整不同版本Deployment的副本数,即可调整不同版本服务的权重,实现灰度发布。
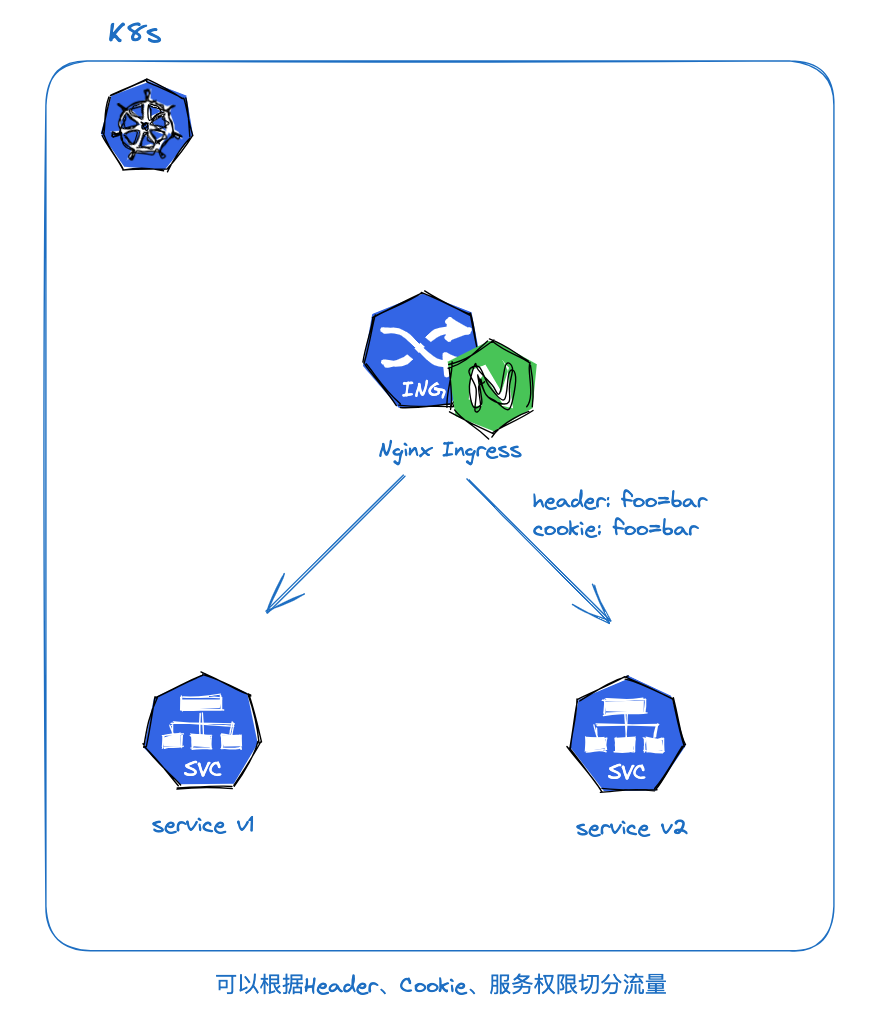
通过Nginx Ingress。Nginx Ingress 则更加强大一些,支持基于Header、Cookie和服务权重三种流量切分的策略
还有很多实现手段,因为不是本文的重点,就不赘述了。如果大家有更好更简单的方式也可以评论区交流。
那如果按照上文讲的微前端部署方式,怎么实现子应用灰度呢?
这里不需要用到复杂的流量分发技术,因为基座自己会收集子应用的信息,那么只需要在子应用注册表上做文章就行了。例如:
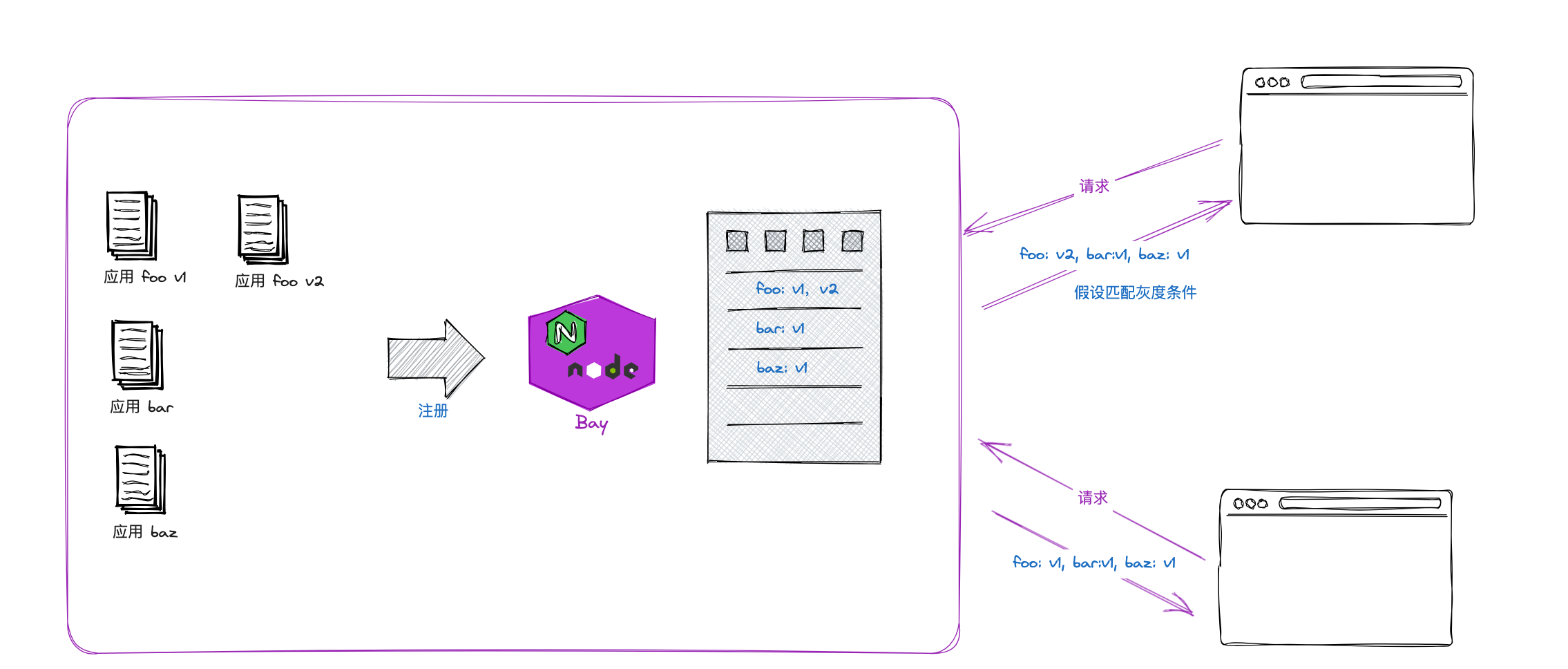
基座会收集到所有的已部署的子应用。一个子应用可能有多个版本。子应用版本之间使用版本号区分目录:
/apps/
foo/
v1/
manifest.json # 应用描述信息
index.html
js/
...
v2/
manifest.json
index.html
js/
...
current.json # 保存当前对外服务的应用版本信息。实际上也可以保存一些灰度条件匹配之类的配置信息
bar/
v1/
manifest.json
current.json
...
- 基座会提供一个管理平台,供运维和开发者 pick 要对外服务的版本,或者配置灰度匹配条件等等。
- 当浏览器发起入口文件请求时,基座计算最终要返回的子应用配置列表,不同人群可能拿到的结果不一样,从而实现灰度发布功能。
这个思路看起来和后端的服务发现平台(比如 Nacos)很像,后端服务实现灰度基本也是依靠这些平台来实现的。
总结
回顾一下本文。Docker 发布已经十年,大家对它应该已经熟悉不过了,它对现代的软件工程有非常重要的意义。
我在这篇文章中分了两个维度来讨论它, 一是将它作为一个’跨平台’的任务运行环境,它让我们可以在一致的环境中运行单测、构建、发布等任务;二是讲怎么将前端应用容器化,对齐后端,利用现有的容器管理平台来实现复杂的部署需求。
复杂的前端应用构建、发布和部署需要考虑很多问题,可以看看知乎:大公司里怎样开发和部署前端代码? 字节这篇文章 2021 年当我们聊前端部署时,我们在聊什么。
扩展阅读
Build With Docker
Dockerfile reference
Dockerfile 多阶段构建
The Twelve-Factor App
ngx_http_ssi_module
Using Environment Variables in Nginx Config File
2021 年当我们聊前端部署时,我们在聊什么
BuildKit 下一代的镜像构建组件