一张图说明Ejs模板引擎的原理

上面一张图,已经大概把一个简单模板引擎(这里以EJS为例)的原理解释得七七八八了。本文将描述一个简单的模板引擎是怎么运作的?包含实现的关键步骤、以及其背后的思想。
基本上模板引擎的套路也就这样了,但这些思想是通用的,比如你在看vue的模板编译器源码、也可以套用这些思想和方法.
基本API设计
我们将实现一个简化版的EJS, 这个模板引擎支持这些标签:
<% script %> - 脚本执行. 一般用于控制语句,不会输出值 例如
<% if (user) { %>
<div>some thing</div>
<% } %>
|
<%= expression %> - 输出表达式的值,但是会转义HTML:
<title>{%= title %}</title>
|
<%- expression %> - 和<%= expr %>一样,只不过不会对HTML进行转义
<%% 和%%> - 表示标签转义, 比如<%%会输出为<%<%# 注释 %> - 不会有内容输出
下面是一个完整的模板示例,下文会基于这个模板进行讲解:
<html>
<head><%= title %></head>
<body>
<%% 转义 %%>
<%# 这里是注释 %>
<%- before %>
<% if (show) { %>
<div>root</div>
<% } %>
</body>
</html>
|
基本API设计
我们将模板解析和渲染相关的逻辑放到一个Template类中,它的基本接口如下:
export default class Template {
public template: string;
private tokens: string[] = [];
private source: string = "";
private state?: State;
private fn?: Function;
public constructor(template: string) {
this.template = template;
}
public compile() {
this.parseTemplateText();
this.transformTokens();
this.wrapit();
}
public render(local: object) { }
private parseTemplateText() {}
private transformTokens() {}
private wrapit() {}
}
|
token解析
第一步我们需要将所有的开始标签(start tag)和结束标签(end tag)都解析出来,我们期望的解析结果是这样的:
[
"\n<html>\n <head>",
"<%=",
" title ",
"%>",
"</head>\n <body>\n ",
"<%%",
" 转义 ",
"%%>",
"\n ",
"<%#",
" 这里是注释 ",
"%>",
"\n ",
"<%-",
" before ",
"%>",
"\n ",
"<%",
" if (show) { ",
"%>",
"\n <div>root</div>\n ",
"<%",
" } ",
"%>",
"\n </body>\n</html>\n"
]
|
因为我们的模板引擎语法非常简单, 压根就不需要解析成什么抽象语法树(AST)(即省去了语法解析, 只进行词法解析). 直接通过正则表达式就可以实现将标签抽取出来。
先定义正则表达式, 用来匹配我们所有支持的标签:
const REGEXP = /(<%%|%%>|<%=|<%-|<%#|<%|%>)/;
|
使用正则表达式逐个进行匹配,将字符串拆分出来. 代码也很简单:
parseTemplateText() {
let str = this.template;
const arr = this.tokens;
let res = REGEXP.exec(str);
let index;
while (res) {
index = res.index;
if (index !== 0) {
arr.push(str.substring(0, index));
str = str.slice(index);
}
arr.push(res[0]);
str = str.slice(res[0].length);
res = REGEXP.exec(str);
}
if (str) {
arr.push(str);
}
}
|
简单的语法检查
Ok,将标签解析出来后,就可以开始准备将它们转换称为‘渲染’函数了.
首先进行一下简单的语法检查,检查标签是否闭合:
const start = "<%";
const end = "%>";
const escpStart = "<%%";
const escpEnd = "%%>";
const escpoutStart = "<%=";
const unescpoutStart = "<%-";
const comtStart = "<%#";
if (tok.includes(start) && !tok.includes(escpStart)) {
closing = this.tokens[idx + 2];
if (closing == null || !closing.includes(end)) {
throw new Error(`${tok} 未找到对应的闭合标签`);
}
}
|
转换
现在开始遍历token。我们可以使用一个有限的状态机(Finite-state machine, FSM)来描述转换的逻辑.
状态机是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。简单而言,有限状态机由一组状态、一个初始状态、输入和根据输入及现有状态转换为下一个状态的转换函数组成。它有三个特征:
- 状态总数是有限的。
- 任一时刻,只处在一种状态之中。
- 某种条件下,会从一种状态转变到另一种状态
稍微分析一下,我们模板引擎的状态转换图如下:
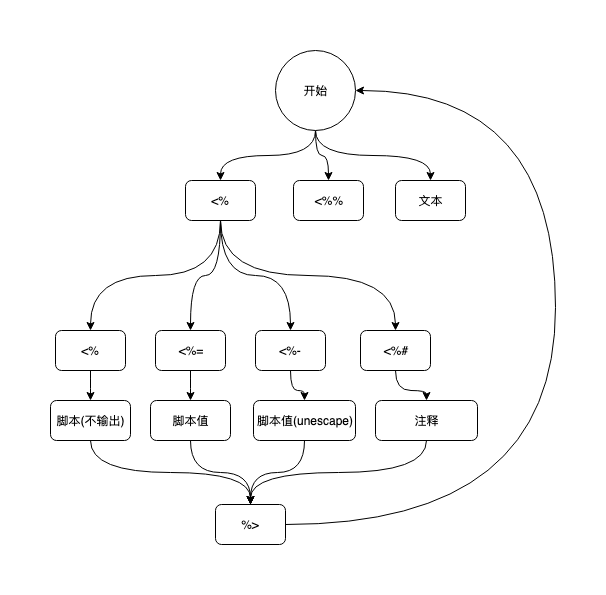
通过上图可以抽取出以下状态:
enum State {
EVAL,
ESCAPED,
RAW,
COMMENT,
LITERAL
}
|
Ok, 现在开始遍历token:
this.tokens.forEach((tok, idx) => {
switch (tok) {
case start:
this.state = State.EVAL;
break;
case escpoutStart:
this.state = State.ESCAPED;
break;
case unescpoutStart:
this.state = State.RAW;
break;
case comtStart:
this.state = State.COMMENT;
break;
case escpStart:
this.state = State.LITERAL;
this.source += `;__append('<%');\n`;
break;
case escpEnd:
this.state = State.LITERAL;
this.source += `;__append('%>');\n`;
break;
case end:
this.state = undefined;
break;
default:
if (this.state != null) {
switch (this.state) {
case State.EVAL:
this.source += `;${tok}\n`;
break;
case State.ESCAPED:
this.source += `;__append(escapeFn(${stripSemi(tok)}));\n`;
break;
case State.RAW:
this.source += `;__append(${stripSemi(tok)});\n`;
break;
case State.LITERAL:
this.source += `;__append('${transformString(tok)}');\n`;
break;
case State.COMMENT:
break;
}
} else {
this.source += `;__append('${transformString(tok)}');\n`;
}
}
});
|
经过上面的转换,我们可以得到这样的结果:
;__append('\n<html>\n <head>');
;__append(escapeFn( title ));
;__append('</head>\n <body>\n ');
;__append('<%');
;__append(' 转义 ');
;__append('%>');
;__append('\n ');
;__append('\n ');
;__append( before );
;__append('\n ');
; if (show) {
;__append('\n <div>root</div>\n ');
; }
;__append('\n </body>\n</html>\n');
|
最后一步,生成函数
现在我们把转换结果包裹成函数:
wrapit() {
this.source = `\
const __out = [];
const __append = __out.push.bind(__out);
with(local||{}) {
${this.source}
}
return __out.join('');\
`;
this.fn = new Function("local", "escapeFn", this.source);
}
|
这里使用到了with语句,来包裹上面转换的代码,这样可以免去local对象访问限定前缀。
渲染方法就很简单了,直接调用上面包裹的函数:
render(local: object) {
return this.fn.call(null, local, escape);
}
|
跑起来
const temp = new Template(`
<html>
<head><%= title %></head>
<body>
<%% 转义 %%>
<%# 这里是注释 %>
<%- before %>
<% if (show) { %>
<div>root</div>
<% } %>
</body>
</html>
`);
temp.compile();
temp.render({ show: true, title: "hello", before: "<div>xx</div>" })
|
你可以在CodeSandbox运行完整的代码:

总结
本文其实受到了the-super-tiny-compiler启发,实现了一个极简的模板引擎,其实模板引擎本质上也是一个Compiler,通过上文可以了解到一个模板引擎编译有三个步骤:
解析 将模板代码解析成抽象的表示形式。复杂的编译器会有词法解析(Lexical Analysis)和语法解析(Syntactic Analysis)
词法解析, 上文我们将模板内容解析成token的过程就可以认为是‘词法解析’,它会将源代码拆分称为token数组,token是一个小单元,表示独立的‘语法片段’。
语法解析,语法解析器接收token数组,将它们重新格式化称为抽象语法树(Abstract Syntax Tree, AST), 抽象语法树可以用于描述语法单元, 以及单元之间的关系。 语法解析阶段可以发现语法问题。
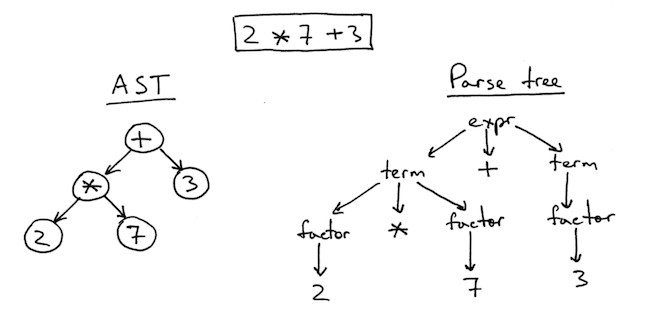
(图片来源: https://ruslanspivak.com/lsbasi-part7)
本文介绍的模板引擎,因为语法太简单了,所以不需要AST这个中间表示形式。直接在tokens上进行转换
转换 将上个步骤抽象的表示形式,转换成为编译器想要的。比如上文模板引擎会转换为对应语言的语句。复杂的编译器会基于AST进行‘转换’,也就是对AST进行‘增删查改’. 通常会配合Visitors模式来遍历/访问AST的节点
- 代码生成 将转换后的抽象表示转换为新的代码。 比如模板引擎最后一步会封装成为一个渲染函数. 复杂的编译器会将AST转换为目标代码
编译器相关的东西确实很有趣,后续有机会可以讲讲怎么编写babel插件。
扩展