2023年了,我还是选择 MobX

时至今日,前端的各种状态管理方案仍层出不穷,花式百样,争议不断,尤其是 React 社区。那我为什么要“背道而驰”,选择基本没什么声音的 MobX 呢?
这篇文章会深入探讨 MobX 背后的面向对象范式之争,以及可变数据与不可变数据之争。篇幅有点长,读者耐心读读会有收获。在阅读时,建议多留意一下目录,把握整篇文章叙述结构。
面向对象与函数式之争
首当其冲的是面向对象和函数式编程之争。MobX 背后代表的是面向对象思想 。
我问 ChatGPT, 面向对象的优势是什么:
**🤖 ChatGPT 曰:
面向对象编程可以将复杂的现实世界中的问题抽象成易于理解和管理的对象,通过对象之间的交互来解决问题。这种对象抽象的方法可以使得程序设计更加直观、简单,可以更好地描述复杂系统中的各个组成部分和它们之间的关系。**
面向对象编程(Object-oriented programming)具有以下优势:
- 抽象化:通过面向对象编程,可以将复杂的现实世界中的问题抽象成易于理解和管理的对象,并通过对象之间的交互来解决问题。这种抽象化的方法使得程序设计更加直观、简单,使得开发人员更容易理解和维护代码。
- 封装性:面向对象编程提供了封装的机制,将对象的属性和方法封装在一起,只暴露必要的接口给外部使用,避免了对内部实现细节的直接暴露,从而提高了代码的安全性和可维护性。
- 继承性:面向对象编程提供了继承的机制,通过继承,子类可以继承父类的属性和方法,并在此基础上进行扩展和修改。这种继承的机制可以避免代码重复,提高代码的可重用性和可维护性。
- 多态性:面向对象编程提供了多态的机制,通过多态,同一种方法可以在不同的对象上产生不同的行为。多态性可以提高程序的灵活性和可扩展性,使得程序更加适应复杂多变的需求。
- 代码复用:面向对象编程提供了模块化的机制,可以将代码分解成多个模块,实现代码的复用和重构。这种模块化的机制可以使得代码更加易于管理和维护,提高了代码的可重用性和可维护性
这是一个教科书式的回答。
抽象能力
我又问 ChatGPT, 在抽象能力上面向对象相比函数式有什么优势?
🤖 ChatGPT 曰:
在抽象能力上,面向对象和函数式编程都有其独特的优势。
面向对象编程的优势在于其能够将复杂的问题抽象成对象,并通过对象之间的交互来解决问题。面向对象编程提供了封装、继承、多态等机制,可以将代码分解成多个独立的模块,使得代码更加易于维护和修改,减少了代码的耦合,提高了代码的灵活性和可维护性。在面向对象编程中,对象是程序的基本组成单元,对象之间通过消息传递来实现交互,从而实现了高度的抽象能力。面向对象编程还提供了丰富的设计模式,可以帮助开发人员更好地组织和管理代码,提高代码的可读性、可维护性和可扩展性。
函数式编程的优势在于其强调函数的纯度和不可变性,可以将函数看作是数学中的函数,而不是过程式编程中的函数。函数式编程提供了高阶函数、闭包、柯里化等机制,可以将函数看作是一等公民,可以进行组合、抽象和重用,从而实现了高度的抽象能力。在函数式编程中,函数是程序的基本组成单元,函数之间通过函数调用来实现交互,从而实现了高度的模块化和组合能力。函数式编程还提供了丰富的函数组合和递归等技术,可以帮助开发人员更好地组织和管理代码,提高代码的可读性、可维护性和可扩展性。
总的来说,在抽象能力上,面向对象和函数式编程都具有其独特的优势,可以根据具体的应用场景选择适合的编程范式。
又一个教科书式的回答,谁都不得罪,请收下我的膝盖!
ChatGPT 回答总是那么八面玲珑,它也知道应该规避二元论,世界上并没有绝对的非黑即白。因此,我们脱离场景去讨论孰好孰坏,都是在耍流氓。
我们将上面 ChatGPT 的回答再归纳一下:
| 面向对象 | 函数式 | |
|---|---|---|
| 抽象单位 | 对象 | 函数 |
| 行为和数据的关系 | 数据和行为合并。强调现实世界问题的抽象还原。 | 数据和行为分离。强调数据不可变性、行为无副作用 |
| 机制 | 封装、继承、多态等 | 高阶函数、闭包、柯里化、递归等 |
| 抽象能力实现 | 对象之间的交互、引用 | 函数组合 |
OK,我觉得文章都让 ChatGPT 来写好了,继续问:分别举一些面向对象和函数式擅长的场景
🤖 ChatGPT 曰:
面向对象编程和函数式编程各有擅长的场景,具体如下:
面向对象编程:
- GUI 编程:面向对象编程可以很好地用于 GUI 编程,因为 GUI 程序通常涉及到许多对象之间的交互,面向对象编程可以将这些对象和它们之间的关系进行抽象和封装,从而使得程序更加易于理解和管理。
- 游戏开发:面向对象编程可以很好地用于游戏开发,因为游戏通常涉及到许多对象之间的交互,面向对象编程可以将这些对象和它们之间的关系进行抽象和封装,从而使得游戏逻辑更加易于理解和管理。
- 企业级应用:面向对象编程可以很好地用于开发大型的企业级应用,因为企业级应用通常需要涉及到多个模块之间的交互,面向对象编程可以将这些模块和它们之间的关系进行抽象和封装,从而使得程序更加易于理解和管理。
函数式编程:
- 并发编程:函数式编程可以很好地用于并发编程,因为函数式编程强调不可变性和无副作用,可以避免并发问题,使得并发编程更加安全和可靠。
- 数据分析:函数式编程可以很好地用于数据分析,因为函数式编程提供了丰富的高阶函数和数据处理函数,可以方便地处理和分析大量的数据。
- 数学计算:函数式编程可以很好地用于数学计算,因为函数式编程强调函数抽象和高阶函数,可以方便地实现数学函数和算法,使得数学计算更加简单和高效。
总之,面向对象编程和函数式编程各有擅长的场景,需要根据具体的应用需求来选择合适的编程范式
有人说:面向对象就是计算机软件对现实世界的阐述,当我们能直观的描述业务场景,就能很好的编写代码。
面向对象的优势在于可以将复杂的现实世界中的问题抽象成易于理解和管理的对象。换句话说它可以比较直接/自然地表达业务对象和业务关系。这个比较契合人类对这个世界的朴素理解。
比如 DDD(一个用来应对复杂业务的研发方法论) 方法论中,基本都以面向对象作为它的建模范式,因为面向对象编程能够直观地表达 DDD 中的模型概念。
💡 也有使用函数式来实现 DDD 的,非常少见
💡 即使是面向对象编程中,通常也会面临“贫血模型” 和 “充血模型” 之争。采用充血模式大概率是某些技术上的妥协。
按照「正统」的面向对象思想,对象是充血的,有血(数据)有肉(行为)的对象。DDD 中也是鼓励使用充血模型。
在前端领域, 面向对象范式在很多场景也有很大的优势:
- 游戏开发。这是面向对象的传统强项,游戏通常包含许多不同类型的对象,如角色、道具、地图等等。利用面向对象编程的优势,可以更加方便地对这些对象进行管理和操作,从而实现更加复杂和精细的游戏系统
- 复杂的交互客户端。比如图像处理软件、低代码编辑器,这类「重」前端软件。
- 复杂的业务系统。比如 ERP、电子商务。比较少见,因为前端业务通常比较薄。
这些场景共有的特征是:它们有复杂的数据结构和对象关系,这些对象之间需要紧密合作才能完成业务。
比如面向对象可以直观地表示树、图这种复杂的关系:
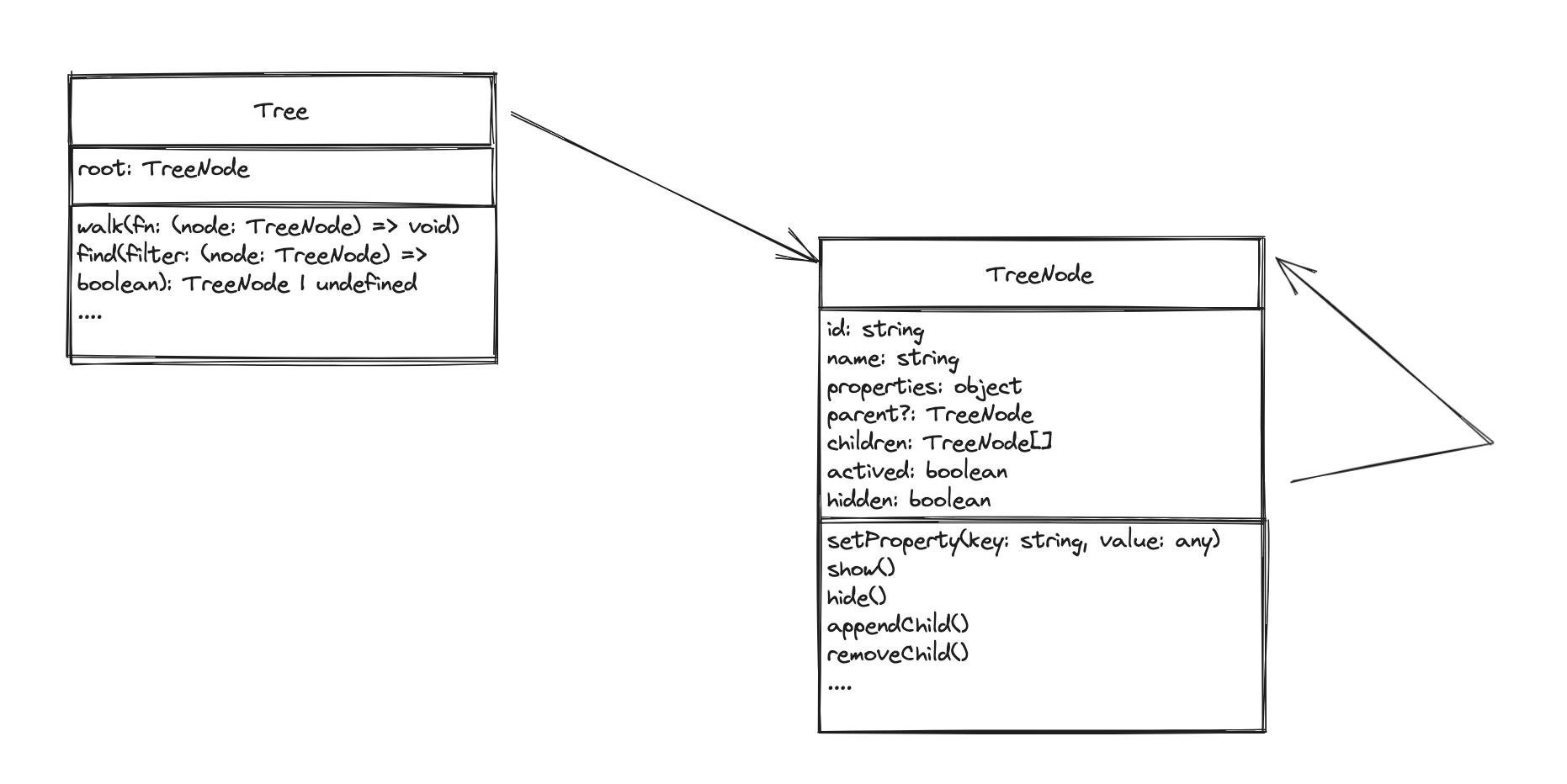
面向对象语言提供了成熟的抽象机制(类、接口、继承、属性、方法、访问控制、多态)、社区上也沉淀了丰富的设计方法论(设计模式、UML、DDD)。
更神奇的是,面向对象曾经被认为是 GUI 开发的不二法门,当然这个已经被 React 等框架打破了,在前端领域,类函数式/数据驱动引领的 UI 开发已经是主流,甚至影响了平台(比如 Flutter, SwiftUI)。
再来看看,目前比较主流的状态管理方案, 比如 Redux/Redux Toolkit、Zustand、Recoil、Pinia等等。
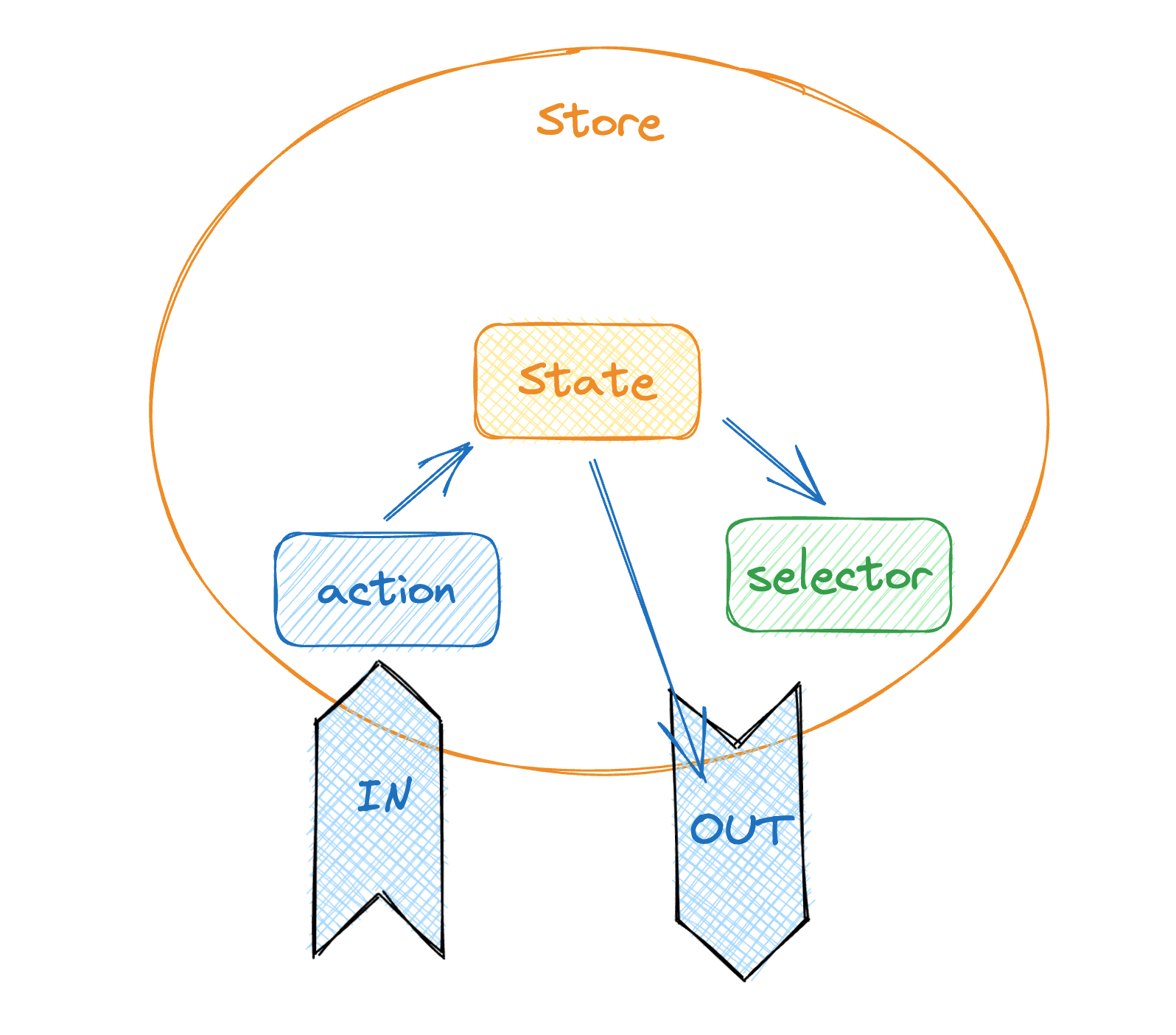
这类以状态(State)为中心的状态管理器中,任何对象都只是一个序列化文档的一个片段(slice)。
💡 就是一个对象文档,从后端的角度看来,这些就是
DTO这类的结构化对象,没有业务含义,只是数据。
// 伪代码 |
这类状态管理方案,在面临复杂的对象关系时,有以下缺陷:
没有更细的粒度(模块)。
这类方案通常只支持 Store 水平分割(slice,本质上最终都会合入一个全局的树,对象之间没有清晰的边界)。
面向对象方案则以对象为抽象粒度,可以随意组合,来表示复杂的事物关系。而函数式编程语言的一等公民——函数,尽管它有灵活的复合能力,它非常擅长处理数据,但无法在对象关系上发挥太多作用。
无法表达引用关系。
这些状态都是
Plain Data,通常还是不可变数据,无法维持稳定的内存引用 , 难以传递引用。行为和数据结构不是亲密绑定。
这也是面向对象和函数式的主要区别,函数式主导数据和行为分离。
// zustand
export const createBearSlice = (set) => ({
bears: 0,
addBear: () => set((state) => ({ bears: state.bears + 1 })),
eatFish: () => set((state) => ({ fishes: state.fishes - 1 })),
})尽管这类
状态管理库看上去将数据和行为组织在一起,但是和类还是有本质的区别:- 体现在了调用方式上。类体系下,我们可以用 object.method() 形式,而 store 体系下,我们通常需要自行传递上下文: store.method(object)。
- 在传递上。比如将数据传递给视图或者某个组件:面向对象通常直接传递对象或者模型,我们可以在这个对象上直接访问相关的数据和行为,对象本身是
自包含的;而函数式,传递的是数据,就只有数据。
裸露的数据。数据结构通常应该作为一种内部的实现细节封装起来,目前大部分 类 Redux 库都无法实施访问控制,更别说是抽象了(比如接口)。
毕竟现在是数据驱动视图的时代,我们通常不认为「数据」就是内部实现。
不支持复杂的数据结构
不过面向对象也可能走向另外一种极端,就是过度设计、过度抽象,导致抽象的层级过深,最终也丧失的透明性。典型的症状是:什么都要套用一下设计模式、大量的类、类层级深、过渡的分层。
笔者看来,应该将面向对象当做一个朴素的业务对象/关系映射器,所谓的过度设计/抽象,不过是提前设想了多余的场景,杀鸡用了牛刀。这其实是每个技术人都会犯的毛病。
约束
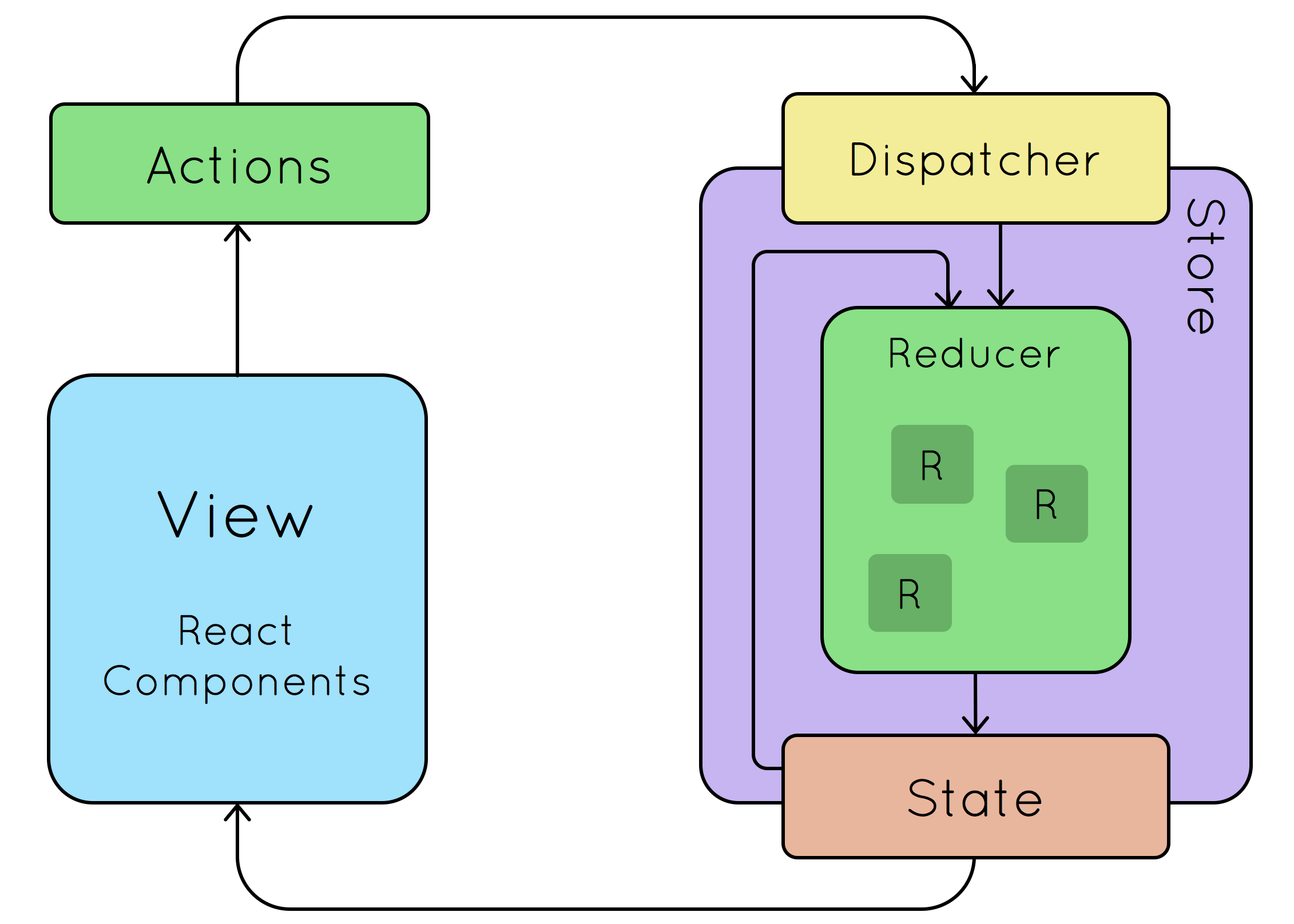
这些类 Redux 状态管理库,通常都有类似的规约,如上图。单向数据流、数据和行为分离、数据只能通过 actions/dispatch 修改、使用 selector 计算状态等等。
为了履行这些规约,这些库通常会创造一套自己的 DSL 。
在这些规约下,一方面,代码可以保持一致性。另一方面,可以最大程度,确保用户按照库的理念执行,并保证用户可以安全地享受库提供的便利(比如调试、时间旅行、镜像),实现双赢:
Pinia 示例
// pinia 示例 |
在 MobX 这类面向对象的方案上, 并没有统一约束和指导。 MobX 文档上唯一相关的指导就是 定义数据存储。

好事!我们站起来了,没有镣铐,我们自由了。我们可以随意组织自己的代码,应用各种牛逼的设计模式。
但是怎么把钱了挣?我们只知道面向「对象」,我们有太多选择。没有任何约束,组织松散,每个人的代码可能都不一样,可能项目就会很快失控,越来越糟糕…
💡 其实 MobX 社区也有其他选项,那就是 https://github.com/mobxjs/mobx-state-tree 和 mobx-keystone,只不过还是得跪着。
所以站着挣钱很难。文章的进度条还很长,后面我还会继续讲这些约束。
说一句宽慰自己的话:关键还看人,设计完全看开发者经验和组织,Redux 有严格的数据变更和订阅约束,照样可以写出面条、巨石代码。
返璞归真
时尚的潮流总是那么飘忽不定:
- 有人叫嚣着去 Typescript
- Alpine.js 说它能免构建运行,就跟“以前”一样
- 别用 tailwindcss,用 unocss
- React 换名字叫 PHP
- …
2023 要返璞归真,放弃追求时尚,Less is more,回归朴素编程。
第一个示范就是用好编程语言提供的原生能力。
在 JavaScript/Typescript 或者其他主流编程语言,面向对象都是原生公民,功能成熟而强大,我们可能真的不需要其他的轮子。
我们可以举一些返璞归真例子:
- RESTful。这是一个大家都知道,也是最容易被误用规范。可以 RESTful 实际上并没有发明新的技术,它就是 HTTP 原本样子,比如 URL 表示服务器的资源,HTTP METHOD 表示对资源的操作方式,用 HTTP STATUS 表示操作的状态… 目前多少声称自己是 REST API, 然后自己重新发明了野生协议?
- React vs Vue。另一个例子是 React 和 Vue,在 React 中组件就是一个纯粹的函数,所有输入都在一个 props 中,不需要区分属性,事件还是插槽,组件树就是函数的“复合”,不需要学习 JavaScript 语言之外的概念。这也使得他的 API 非常的简洁和稳定,Typescript 支持也是基本开箱即用。
Vue 引入了较多概念,当然在 Vue 3 下有所改善,如果读者站着库作者的角度上看,Vue 真是复杂不是一丁半点。
Vue,Angular,小程序,越来越多的框架引入了自己的 DSL。好处就是给开发者提供一个受控的开发体验和使用范围,稳定的接口也给了框架实现者也有了更多的优化空间和实现的替换能力。
坏处也比较明显,开发者要学习新的概念和语法;框架实现也会变得复杂,实现者需要保证 DX,需要给 DSL 配套类型检查,编译和测试套件,开发者工具… 这是一个很大的工程
💡 以上说法可能存在争议,两者理念存在差异,Vue 的设计更多是 Port from HTML,而 React 是 Keep in JavaScript
讲这么多,无非那个道理,时尚一直在变,我们除了向外求,也可以向里求。
面向对象就是摆在眼前的,现成的「状态管理」方案。而且复杂的应用不仅仅是状态管理问题,面向对象方案有广泛的适应性。
可变数据与不可变数据之争
两大门派
不可变数据和可变数据是另一处两极分化。
Vue 和 MobX 为代表的可变响应式数据结构,还有 Redux 为代表的不可变数据。
可变数据的好处对是数据的操作符合习惯,毕竟 JavaScript 并不是一门函数式编程语言。这也使得它在变更不可变数据的时候会比较繁琐,且效率也不高的:
import { create } from 'zustand' |
有趣的是,为了像操作可变数据一样“自然”,也有 immer 这些库:
import { produce } from 'immer' |
那何不直接使用可变数据呢?
你问 ChatGPT,它会告诉你不可变数据有很多好处,比如:
安全性:不可变数据类型的值不能被修改,因此在多线程或并发编程中更加安全。避免了数据竞争和数据不一致的问题。
—— JavaScript 是单线程的,基本上不需要考虑这个问题。可预测性:不可变数据类型的值不会被修改,因此程序的行为更加可预测。在调试和测试时更加方便。
—— 数据如果可以被随意修改,导致的 Bug 通常很隐晦,而且很难排查。可缓存性:不可变数据类型的值不会被修改,因此可以进行缓存优化,提高程序的效率。
—— 不可变数据可以被安全地缓存,相对应的基于它的计算结果也可以被缓存。React memo 函数就是基于这种假设。
—— 可以提高比对的效率。可不变数据通常只需要全等比较(===) 就可以判断是否变更。而可变数据引用可能是固定的。
—— 可镜像。比如实现「时间旅行」,可以高效地序列化
可预测性
类 Redux 的状态管理器实际上就是 CQRS(Command and Query Responsibility Segregation) 架构,就是把将应用程序中的读和写操作分离。这种架构在后端 DDD 实现中,也被广泛推荐。
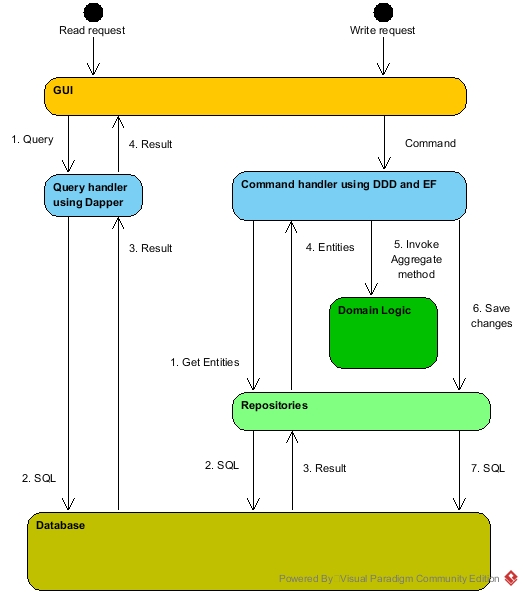
服务端 CQRS 架构
在本文的场景中,CQRS 的主要好处还是实现数据变更的「可预测性」。
我们大可不必像后端程序那样,定义一堆 Query 类、Command 类、QueryHandler 类、CommandHandler 类。
MobX 也提供了 Action 的概念,对于大型项目,我们都推荐只在 action 方法下去变更状态:
import { configure } from 'mobx' |
只允许在 action 中变更状态:
class Todo { |
这样,当状态在 action 之外被修改时,控制台会输出警告。另外配合 MobX 开发工具,我们也可以对这些 Action 和状态进行跟踪。
时间旅行
「时间旅行」是类 Redux 的状态管理器的另一个杀手器。时间旅行可以有两种理解:一个是开发调试上,另一个是应用本身需要具备历史回溯能力(即撤销/重做, 甚至多人协作)。
💡 换句话说,一种是满足开发需求,一种是满足业务需求。
先来看开发调试。时间旅行并不是不可变数据的专属,比如 Vuex、Pinia、MobX-state-tree 这些状态管理库都能做到。它们的实现的条件和过程如下:
- Single Store。Store 是全局的,方便被跟踪
- 配套开发者工具(比如 Redux DevTool, Vue DevTool)。举例 Pinia ,它会在 Action 执行前后触发订阅事件,开发者工具可以在这些事件触发时,对 Store 进行一次镜像拷贝。有了这些镜像历史之后,就可以实现回滚操作啦。
- 另外状态管理库还需要在 HMR、Store Patch 上提供支持。
这种「时间旅行」可以给我们的开发和调试带来极致的体验,很甜。
我们使用野生的面向对象方案,比较难实现这种效果,而且需要开发者工具的支持。 实际上,「时间旅行」的开发体验通常也不是我们选择这类方案的主要原因。
如果想要在 MobX 上实现时间旅行,建议使用 MobX-state-tree
另一种时间旅行是满足业务上的需求,比如实现撤销/重做,甚至多人协作。
针对这种需求,笔者有以下建议:
- Single Store。建议将需要进行’时间旅行‘核心数据聚合到一个类中,而不是分散在不同的 Store,方便对状态进行统一管理(镜像和 patch),实现起来也会简单很多。
- 单向数据流/CQRS 分离。即我们上一节介绍的内容,限制读写分离,避免意外的修改,另外可以将 action 作为一个进行镜像化的时机。
- 如果想要实现多人协作的需求,建议配合更专业
yjs等 CDRT 方案去实现。
对于树状结构的 Store,我们这里就简单介绍一个「镜像化」的思路。假设我们的 Store 是一颗树状结构:
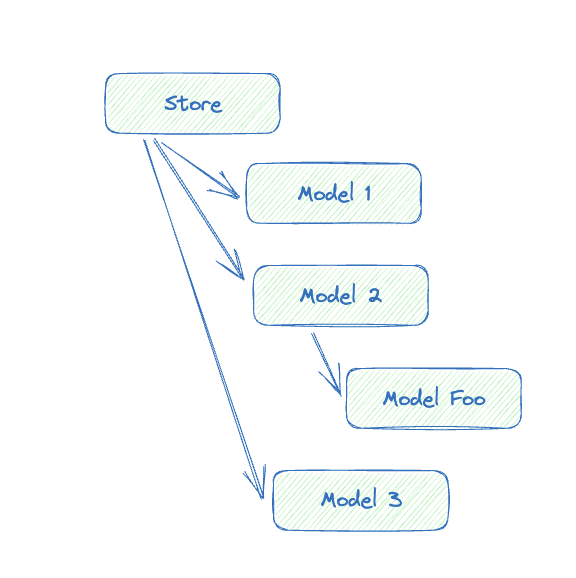
我们可以设计一个 Serializable 接口:
/** |
让需要实现镜像化的 Model 和 Store 都实现这个接口, 我们只需自顶向下调用 toSnapshot 就可以构造一个镜像:
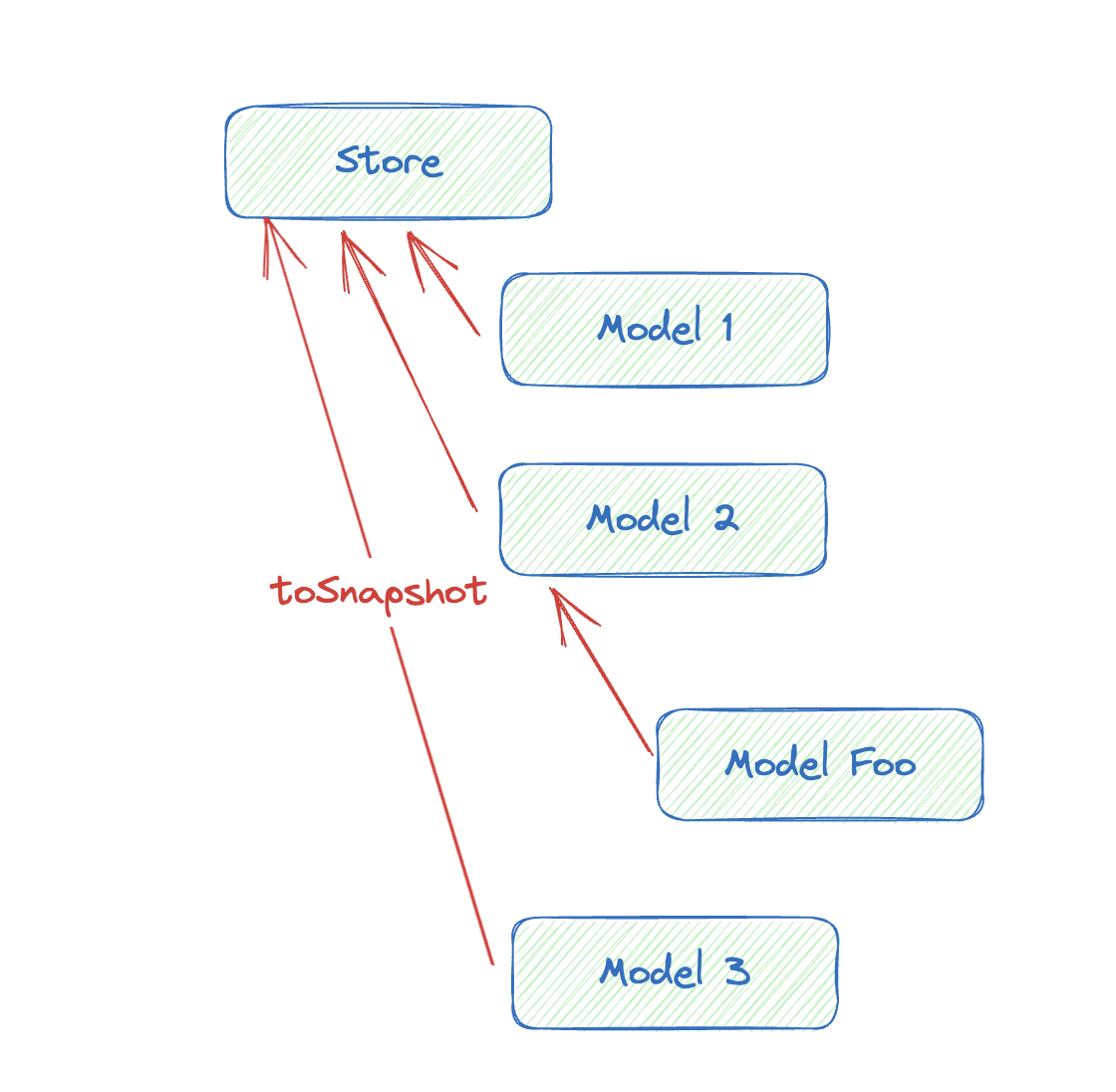
但这种效率并不高,一个小的变动就需要序列化一棵树。我们可以在这个基础上再加上一些脏标记或者版本号之类的,来避免不必要的序列化:
export interface Serializable<T = any> { |
镜像化的过程,类似于 DOM 的事件冒泡机制的形式:
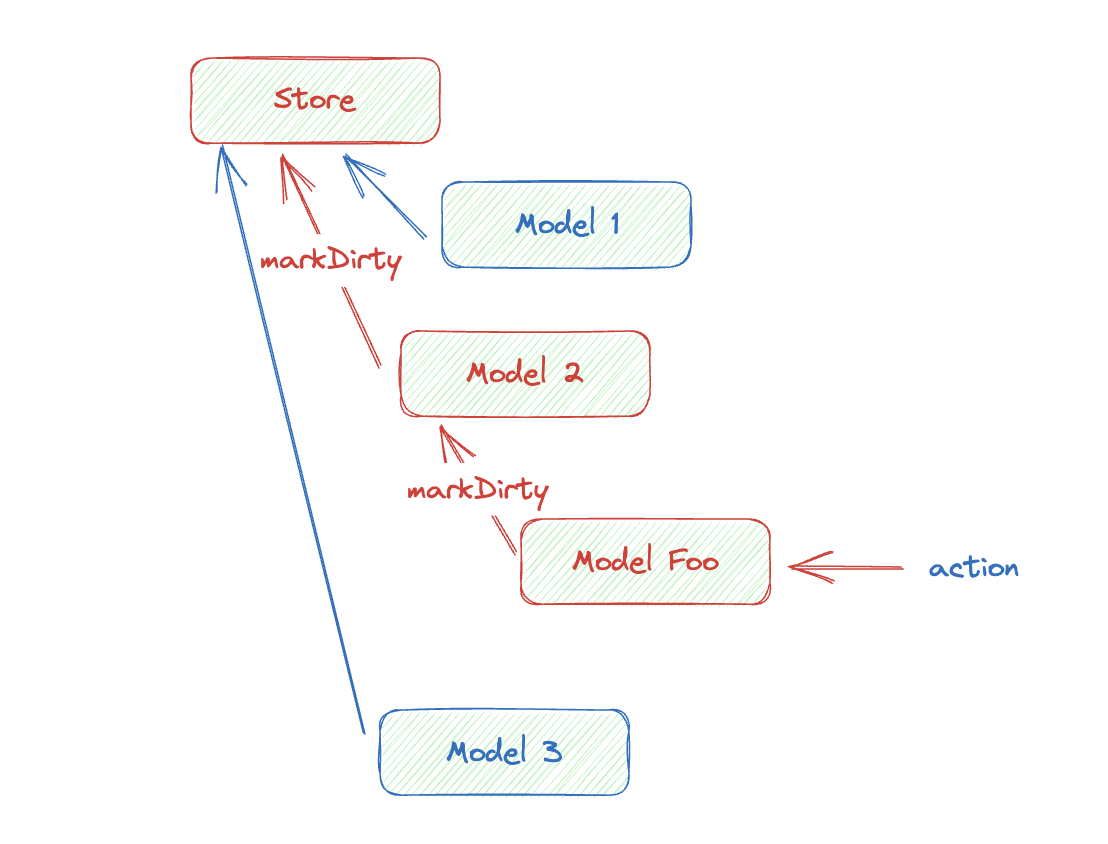
假设我们在 Model Foo 中执行了 Action,我们就将 Model Foo 标记为 dirty,接着冒泡调用父级的 markDirty, 直到根节点终止。接下来,从根节点开始向下递归调用 toSnapshot, 如果节点没有被标记为 Dirty ,那么返回之前缓存的结果就行了。
对于复杂的场景,笔者还是建议配合 yjs 这类库区实现。后续会有专门的文章来介绍这块,敬请期待。
精细渲染
精细渲染是视图框架实现高性能渲染的一个重要方向之一。可变数据和不可变数据的两者各有千秋.
可变数据,我们通常使用响应式数据(事件/订阅模式)的方案,在渲染过程中收集数据订阅,当这些数据变更时,触发对应组件的渲染。
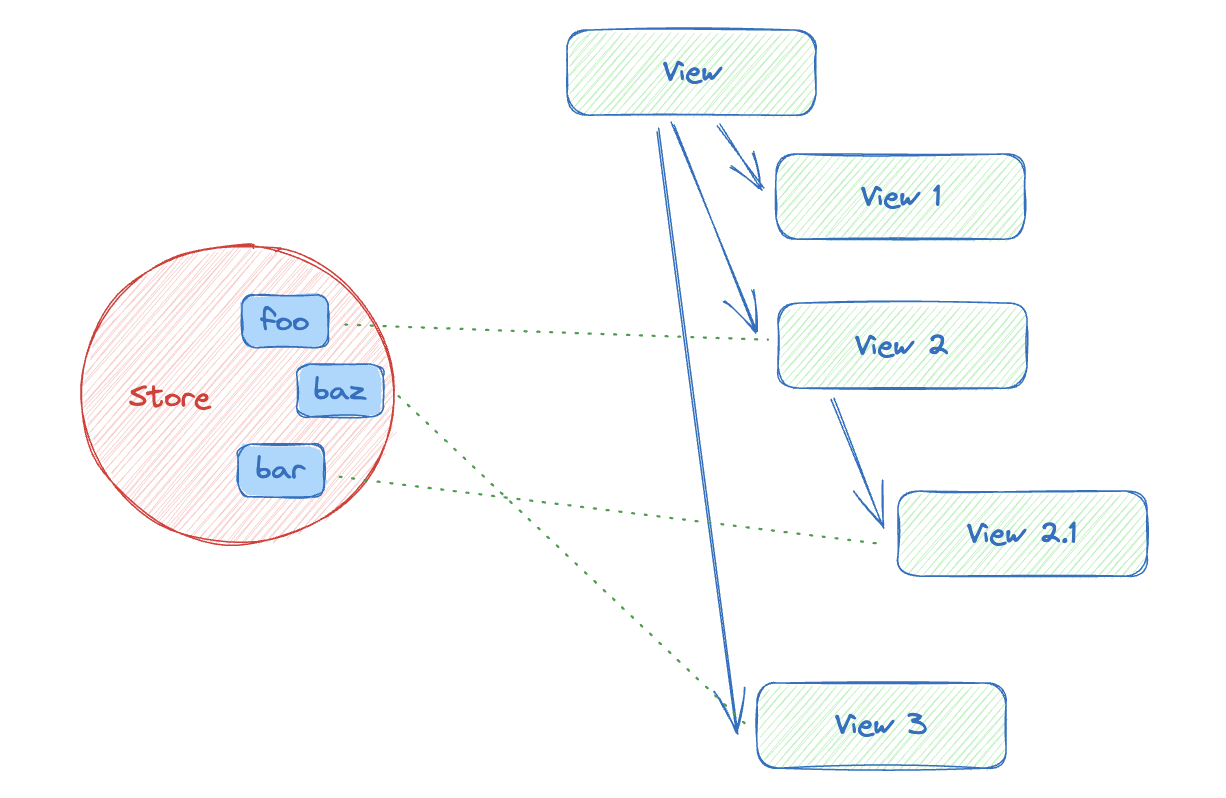
举个例子,View 2.1 订阅了 bar,那么 bar 变更时,仅需重新渲染 View 2.1。
而不可变数据的精细化渲染则是基于不可变数据的可缓存性,那对应的组件就是缓存函数(记忆函数,memoize)。也就是说,如果视图依赖的数据没有变更,那么可以假设不需要重新渲染视图:
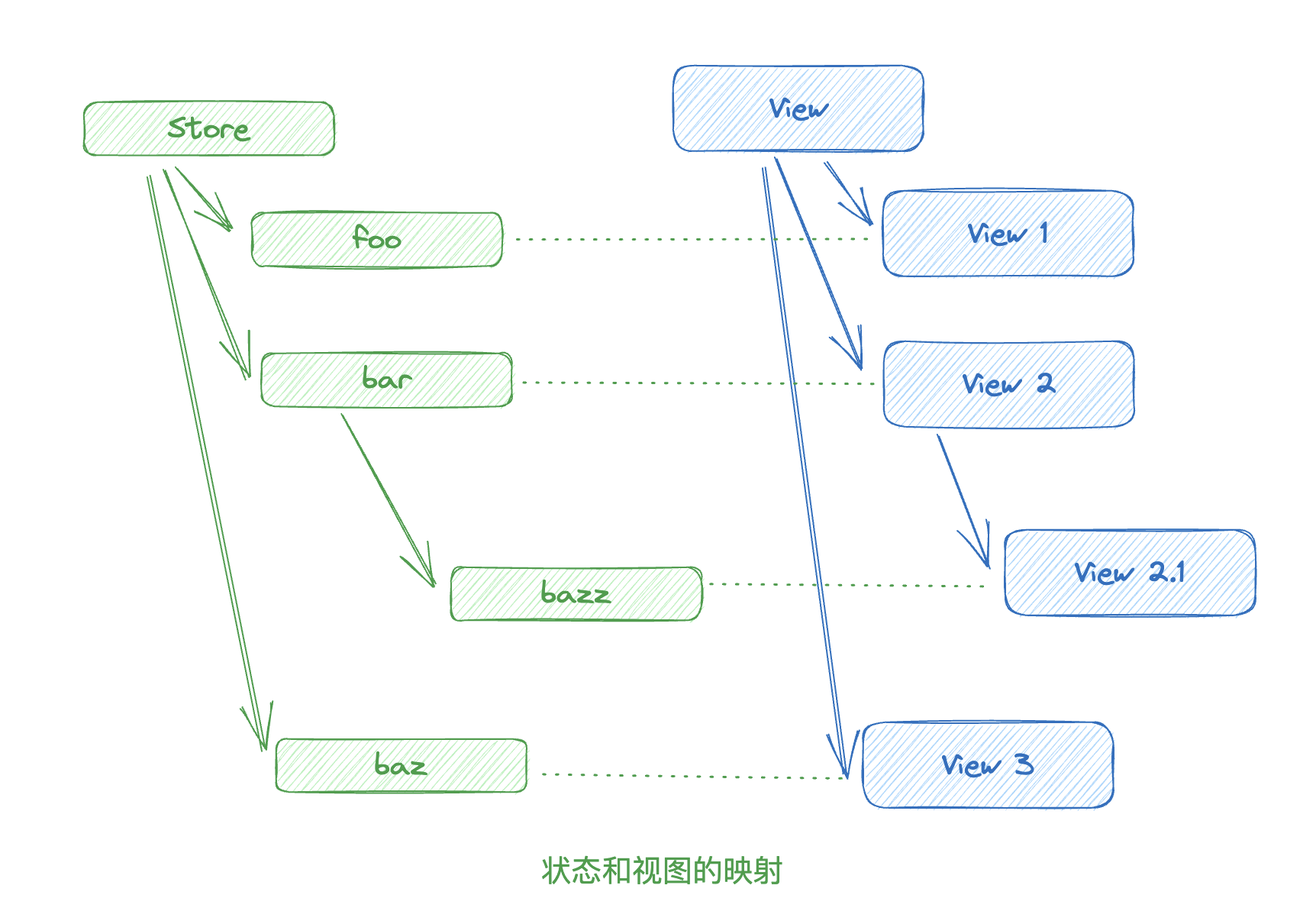
假设 bazz 修改了:
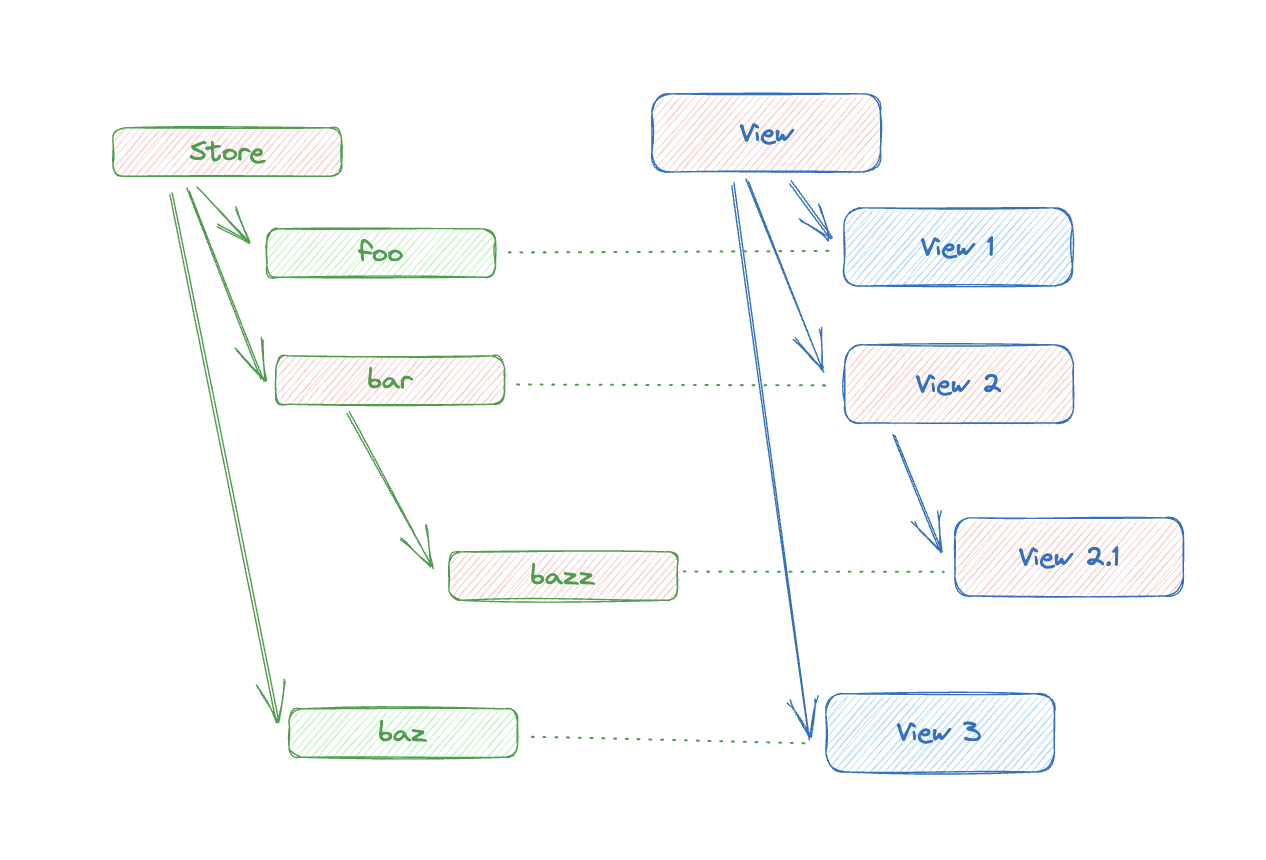
视图层自上而下比对,如果输入(props or state) 不变,就可以跳过渲染。
实际应用中,不可变数据的精细化的实施成本相对较高。如果严格按照这套逻辑,我们通常需要分离状态,将衍生数据、 组件都标记为 memoize (组件使用 React.memo 或 PureComponent,衍生数据使用 useMemo)。
💡 为了解决繁琐的 memo 逻辑,React 在 React Conf 2021 上曾提出过 React Forget 的计划。
Svelte 则是另外一种思路,通过静态编译阶段分析数据变更的影响范围,并生成变更拦截代码。更加精细和高效
结论就是,在精细化渲染方面,响应式数据则更容易实施,没有那么多心智负担,对于初级开发者也不太容易写出性能差的应用。
应用到视图
接下来我们讨论如何将我们的 Store 注入到视图,以及这些 Store 对象生命周期的管理。
注入视图层
视图注入有两种方式。一种是利用视图框架提供的 Context/provide-inject 功能:
// in vue |
稍微封装一下:
interface Disposable { |
大部分简单的场景,这已经足够了。
更复杂的场景,比如 Store 对象之间有复杂的依赖关系,这些对象的作用域和生命周期规则也比较复杂。这时候就可以考虑引入依赖注入方案了, 比如injection-js、inversify、tsyringe。
依赖注入的优势,笔者就不在这里展开说了。下面是笔者公司内部框架的代码示例:
创建模型: CounterModel.ts
import {injectable, page} from '@wakeapp/framework'
import { makeObservable, observable } from 'mobx'
// 声明需求映射
declare global {
interface DIMapper {
'DI.CounterModel': CounterModel
}
}
// 实现
@injectable()
@page()
export class CounterModel {
@observable
count: number = 0
constrcutor() {
makeObservable(this);
}
increment = () => {
this.count++
}
decrement = () => {
this.count--
}
}消费 CounterPage.tsx
import { useInject } from '@wakeapp/framework'
import React from 'react'
import { observer } from 'mobx-react'
// 使用 observer 包裹,让组件可以监听 mobx 响应式数据的变动
export const CounterPage = observer(() => {
const counter = useInject('DI.CounterModel')
return <View onClick={counter.increment}>{counter.count}</View>
})
更多介绍,可以见这里
对象生命周期
模型对象的生命周期如何管理呢?
大部分情况下,我们都不需要复杂的对象生命管理,让它随页面而生,随页面销毁而死就行了,比如上一节提到的第一种视图注入方案。我们只需要在视图根节点或者页面节点创建 Store,在节点销毁时 dispose 掉。
如果使用依赖注入的方式就可以对对象进行更精细的生命周期管理。比如:
| 类型 | 描述 | 挂靠对象 | 场景 |
|---|---|---|---|
| singleton | 单例。在整个应用生命周期内存在,有且只有一个实例 | 应用 | 全局数据,跨页面共享数据 |
| container | 子容器单例。 singleton 实际上就是在全局容器的单例 | 子容器 | 数据隔离 |
| page | 页面。和页面的生命周期挂靠,在当前页面中,有且只有一个实例。 可以认为就是为每个页面创建 container |
页面 | 需要在同一个页面组件层级下共享的数据。 |
| request | 请求。在一次请求中有且只有一个实例。 | 请求 | |
| transient 默认 | 临时。每次请求都会创建一个实例 | 临时数据 |
更详细的介绍可以看看 InversifyJS、tsyringe 等库的文档。注意,大部分情况我们都不需要用到这么复杂的方案。
💡 关于 SSR 的支持,由于篇幅有限,这里就不展开了
MobX in Vue
尽管 MobX 也提供了 Vue 绑定,但是总觉得奇奇怪怪的,实际上也很少人这么用。
那为什么不直接基于 Vue 的 reactive API 封装类 MobX API, 支持使用 class 来编写呢?
export class CounterModel { |
说干就干,相关实现源码请见这里, 我在 《全新 Javascript 装饰器实战上篇:用 MobX 的方式打开 Vue》中也介绍过,这里懒得展开说了。
总结
本文主要探讨笔者为什么选择 MobX 放在自己的武器库中:
- 面向对象 VS 函数式,探讨面向对象范式的优势和适用场景
- 回归朴素编程,利用编程语言原生的能力把事情做好,放弃不必要的约束和时尚
- 现代状态管理库需要处理的各种问题,比如可预测性,时间旅行,精细化渲染
- 最后介绍如何和视图结合,以及管理复杂的对象生命周期
2023 年了,如果视图框架趋于稳定(往服务端方向卷了), 而状态管理器还是一个火山爆发期(可以看看 2023 再看 React 状态管理库)。
我还是坚持还是三年前那句话;大部分情况你不需要状态管理,其次你不需要复杂的状态管理:
- 如果组件或者页面可以做到自包含,那么完全没必要使用状态管理,更没必要为了某些状态管理器的「最佳实践」将状态外部化。
- 你不需要复杂的状态管理。简单的状态管理,可以使用视图框架内置的一些能力,比如 Vue 的 provide/inject, React 的 Context。再复杂的,可以使用与视图框架心智模型相近的方案,比如 Vue + Pinia,React + Hox?
本文的标题是我选择 MobX 的原因,并不代表我推荐你无脑地使用它。
笔者是 MobX 的重度使用者,过去几年在若干复杂的项目中应用过,这些项目不乏有 IM 应用、低代码编辑器、图形编辑器。
如果你的场景再复杂一点,特别是需要能够直观地表达对业务的抽象,对象之间有复杂的交互,那这便是面向对象的强项。当然复杂的应用不仅仅需要状态管理,面向对象方案都有较强的普适性。
不过因为它过于灵活,缺乏约束,不是所有团队都能适应,也很容易写出难以维护的代码。
时至今日,不是 MobX 「热度」不再,而是 MobX 所代表的面向对象范式光芒被暂时屏蔽了。但历史总有峰回路转的时候。