React组件设计实践总结05 - 状态管理
今天是 520,这是本系列最后一篇文章,主要涵盖 React 状态管理的相关方案。
前几篇文章在掘金首发基本石沉大海, 没什么阅读量. 可能是文章篇幅太长了?掘金值太低了? 还是错别字太多了? 后面静下心来想想,写作对我来说是一种学习和积累的过程, 让我学习更全面更系统性去描述一个事物. 但是写作确实是一件非常耗时的事情, 文章的每句话都要细细推敲, 还要避免主观性太强避免误导了别人.
所以模仿<<内核恐慌>>的口号: “想看的人看,不想看的人就别看”
系列目录
文章目录
状态管理
现在的前端框架,包括 React 的一个核心思想就是数据驱动视图, 即UI = f(state). 这种开发方式的变化其实得益于 Virtual-DOM, 它使得我们不需要关心浏览器底层 DOM 的操作细节,只需关心‘状态(state)’和‘状态到 UI 的映射关系(f)’. 所以如果你是初学者,不能理解什么是‘数据驱动’, 还是不推荐继续阅读文章下面的内容。
但是随着 state 的复杂化, 框架现有的组件化方式很难驾驭 f(视图的映射关系变得复杂, 难以被表达和维护); 或者相关类型的应用数据流本来就比较复杂, 组件之间的交互关系多样,本来难以使用UI = f(state)这种关系来表达; 或者应用的组件状态过于离散,需要统一的治理等等. 我们就有了状态管理的需求.
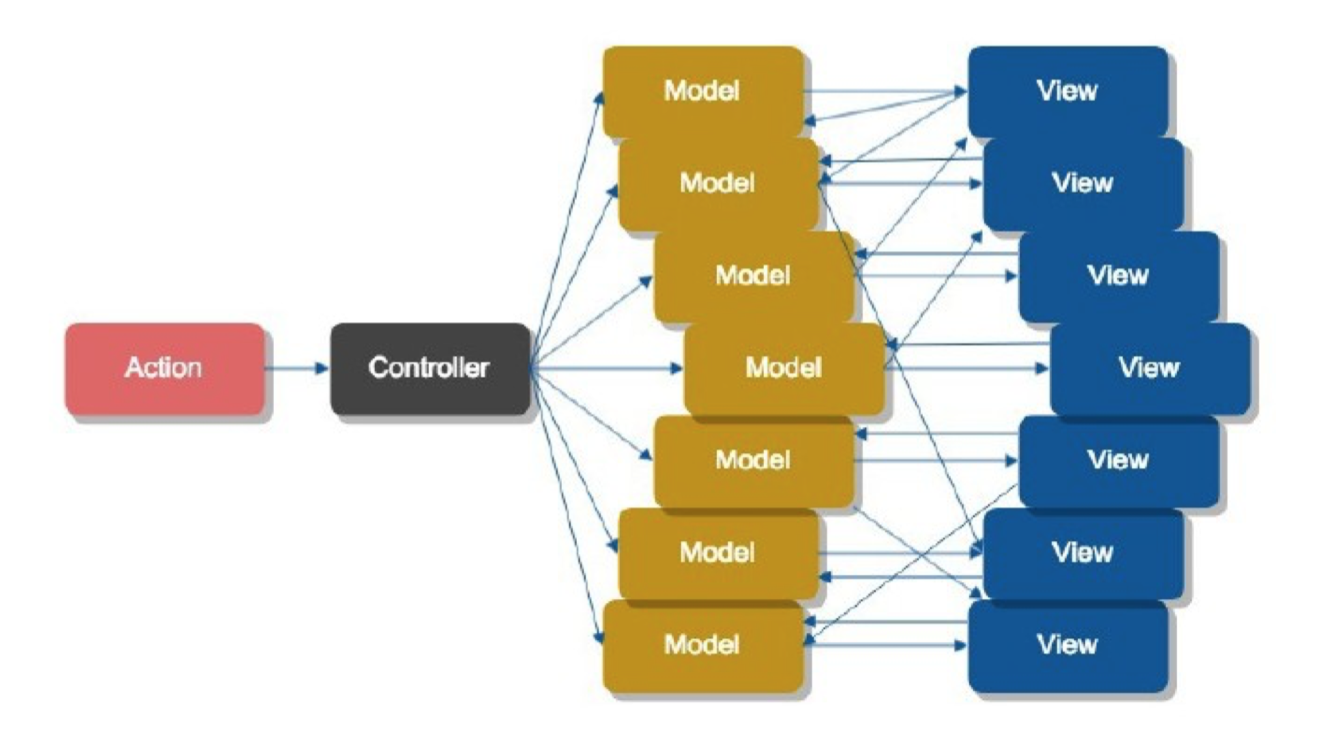
状态管理最基础的解决方式就是分层,也就是说和传统的 MV* 模式没有本质区别, 主流状态管理的主要结构基本都是这样的:
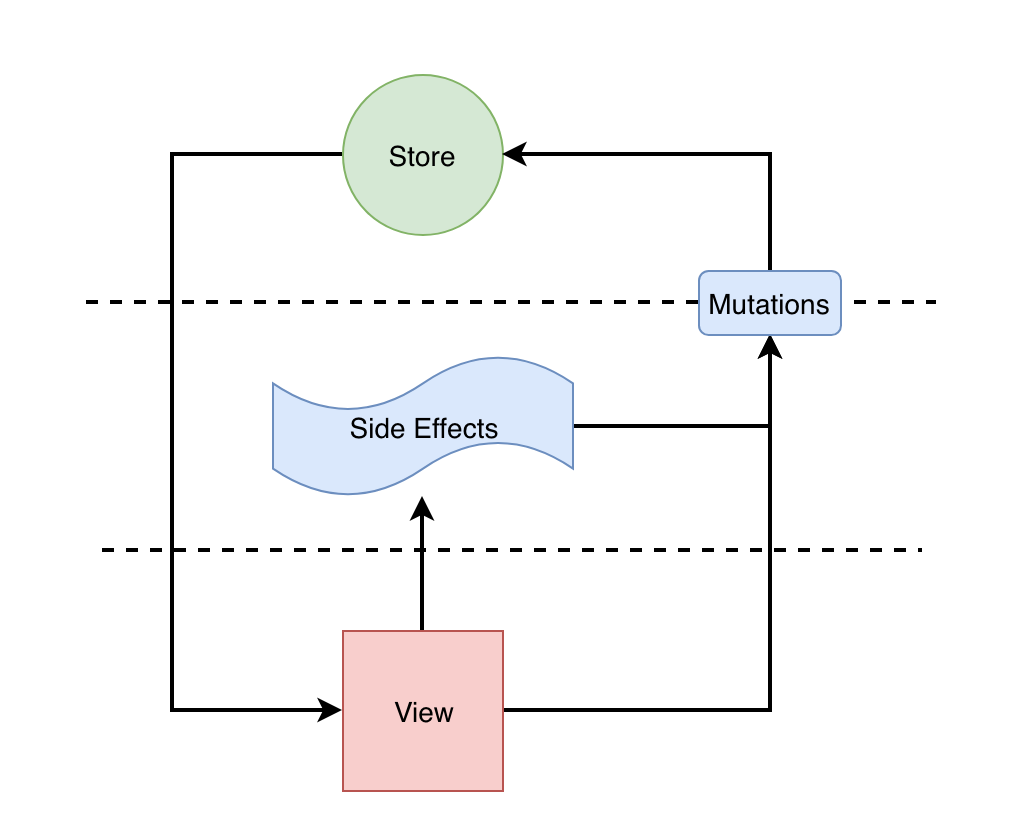
他们基本都包含这些特点:
- 分离视图和状态. 状态管理器擅长状态管理,所以他们一般会将应用状态聚合在一起管理,而视图退化为贫血视图(只关注展示),这样就可以简化
f映射关系, 让UI = f(state)这个表达式更彻底 - 约束状态的变更。Redux 要求通过
dispatch+reducer, mobx 要求数据变更函数使用action装饰或放在flow函数中,目的就是让状态的变更根据可预测性 - 单向数据流。数据流总是按照 Store -> View -> Store 这样的方式流动, 简化数据流
但是, React 的状态管理方案太多了,选择这些方案可能会让人抓狂,你需要权衡很多东西:
- 面向对象还是函数式还是函数响应式?
- 单 Store 还是多 Store?
- 不可变数据还是可变数据?
- 写代码爽还是后期维护爽?
- 自由还是约束?
- 强类型还是弱类型?
- 范式化数据还是非范式化?
- React 原生还是第三方?
- …
你不需要状态管理
对于大部分简单的应用和中后台项目来说是不需要状态管理的。说实话这些应用和传统 web 页面没什么区别, 每个页面都各自独立,每次打开一个新页面时拉取最新数据,增删改查仅此而已. 对于这些场景 React 的组件状态就可以满足, 没有必要为了状态管理而状态管理. 这种各自独立的‘静态’页面,引入状态管理就是过度设计了。
在考虑引入状态管理之前考虑一下这些手段是否可以解决你的问题:
- 是否可以通过抬升 State 来实现组件间通信?
- 如果跨越的层级太多,数据是否可以通过 Context API 来实现共享?
- 一些全局状态是否可以放在 localStorage 或 sessionStorage 中?
- 数据是否可以通过外置的事件订阅器进行共享?
- …
你不需要复杂的状态管理
当你的应用有以下场景时,就要开始考虑状态管理:
- 组件之间需要状态共享。同一份数据需要响应到多个视图,且被多个视图进行变更
- 需要维护全局状态,并在他们变动时响应到视图
- 数据流变得复杂,React 组件本身已经无法驾驭。例如跨页面的用户协作
- 需要统一管理应用的状态。比如实现持久化,可恢复,可撤销/重做
- …
首先确定是否需要 Redux、Mobx 这些复杂的状态管理工具? 在 2019 他们很多功能都可以被 React 本身提供的特性取代. 随着 React 16.3 发布了新的 Context API,我们可以方便地在它之上做简单的状态管理, 我们应该优先选择这些原生态的状态管理方式。
例如: 简单的使用 Context API 来做状态管理:
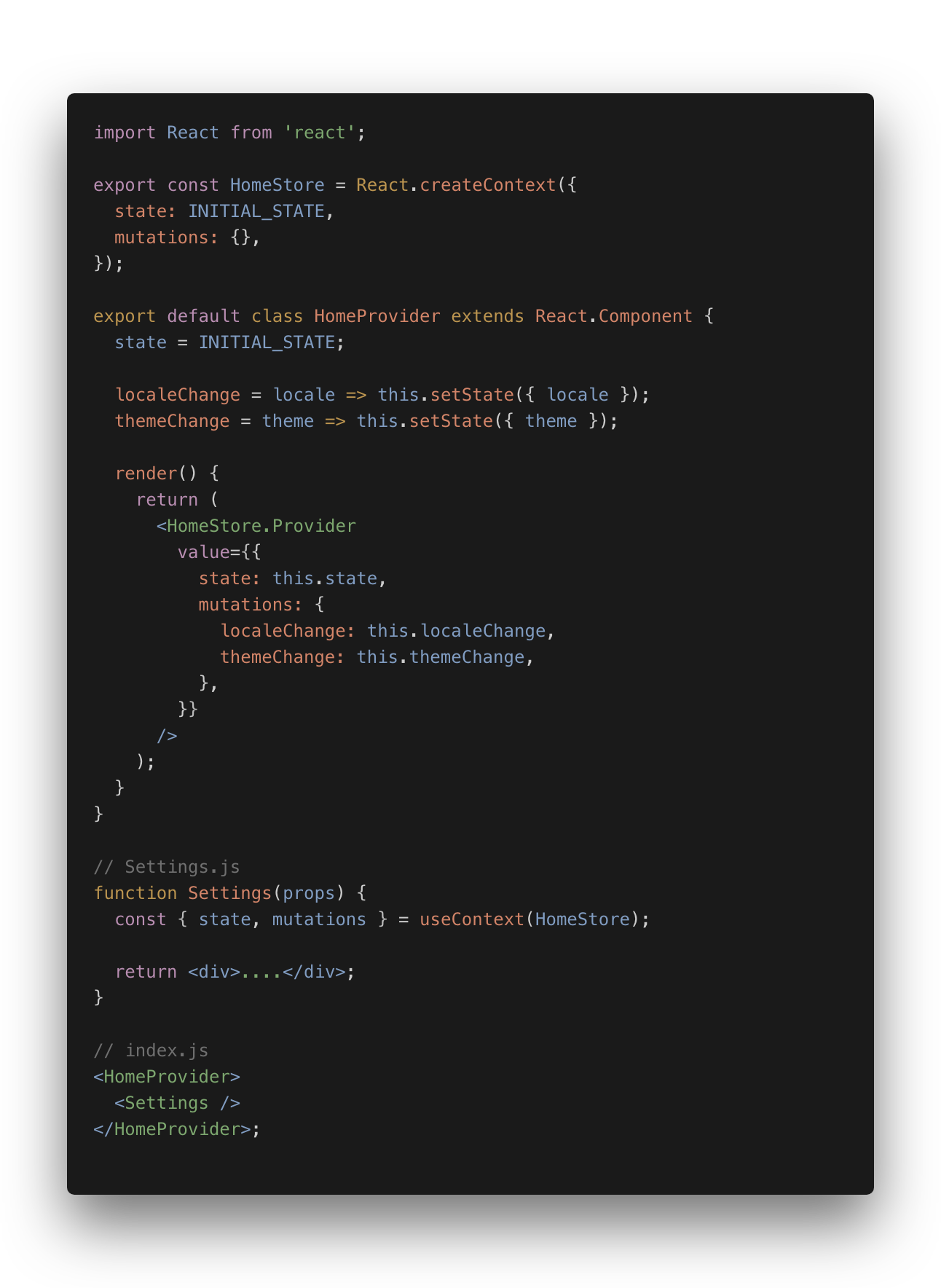
最近 hooks 用得比较爽(参考上一篇文章: 组件的思维),我就想配合 Context API 做一个状态管理器, 后来发现早就有人这么干了: unstated-next, 代码只有 38 行(Hooks+Context),接口非常简单:

依赖于 hooks 本身灵活的特性,我们可以用它来做很多东西, 仅限于想象力. 例如异步数据获取:
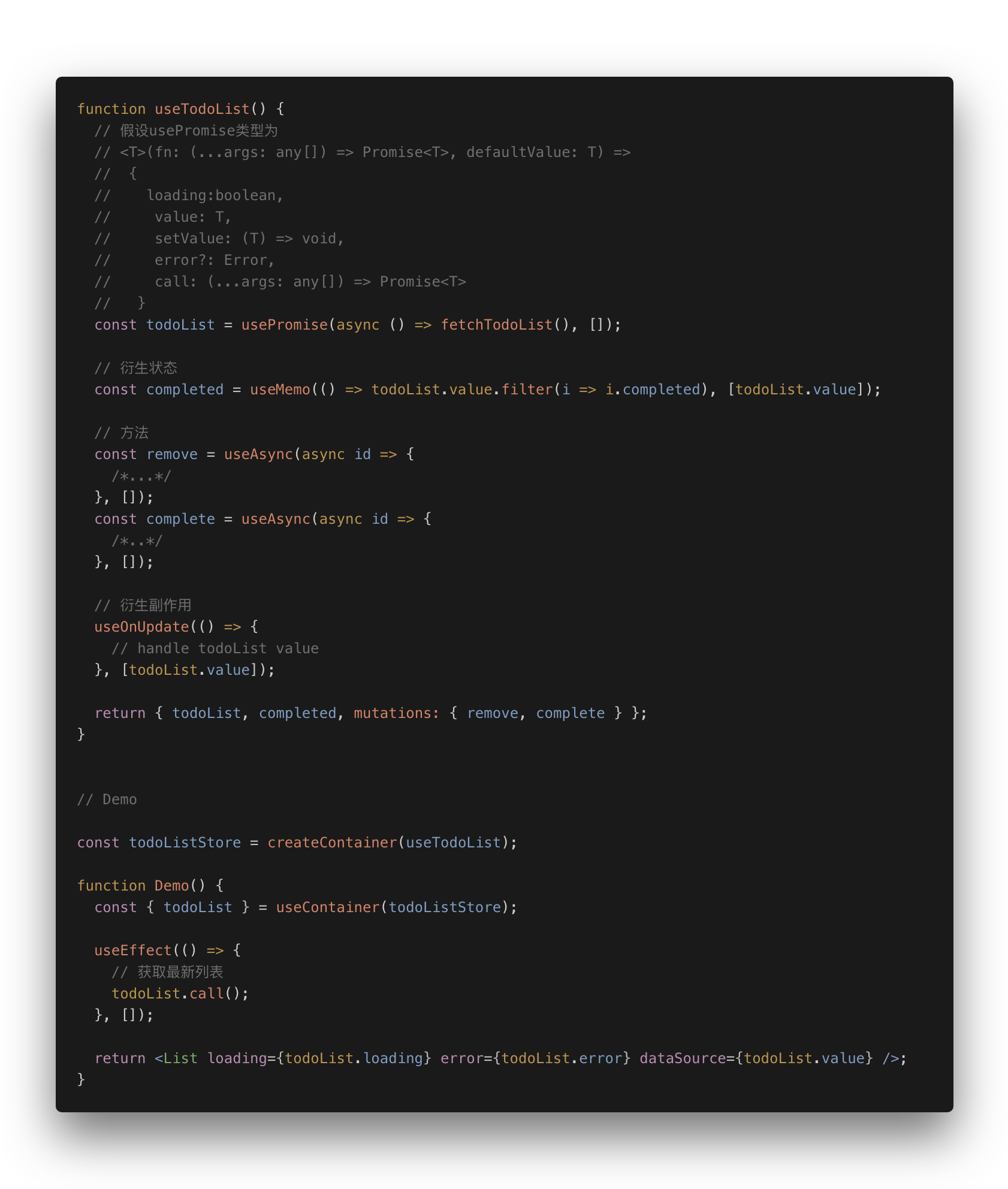
抑或者实现 Redux 的核心功能:
总结一下使用 hooks 作为状态管理器的优点:
- 极简。如上
- 可组合性. hooks 只是普通函数, 可以组合其他 hooks,以及其他
Hooks Container. 上一篇文章提到 hooks 写着写着很像组件,组件写着写着很像 hooks,在用法上组件可以认为是一种’特殊’的 hooks。相比组件, hooks 有更灵活的组合特性 - 以 react 之名. 基于 Context 实现组件状态共享,基于 hooks 实现状态管理, 这个方式足够通用.
- hooks 很多灵活的特性足以取代类似 Mobx 这些框架的大部分功能
- 只是普通的 React 组件,可以在 React inspector 上调试
- 强类型
- 基于Context API更容易实现模块化(或者分形)
需要注意的地方
- 没有外置的状态. 状态在组件内部,没有方法从外部触发状态变更
- 缺少约束. 是好处也是坏处, 对于团队和初学者来说没有约束会导致风格不统一,无法控制项目熵增。好处是可以自定义自己的约束
- 性能优化. 需要考虑 Context 变更带来的性能问题
- 调试体验不如 Redux
- 没有数据镜像, 不能实现诸如事件管理的需求
- 没有 Redux 丰富的生态
所以 Context+ Hooks 可以用于满足简单的状态管理需求, 对于复杂的状态管理需求还是需要用上 Redux、Mobx 这类专业的状态管理器.
其他类似的方案
- unstated unstated-next 的前身,使用 setState API
- react-hooks-global-state
扩展
Redux
unstated 是一个极简的状态管理方案,其作者也说了不要认为unstated 是一个 Redux killer, 不要在它之上构建复杂的工具,也就是不要重复造轮子。所以一般到了这个地步, 其实你就应该考虑 Redux、Mobx、Rxjs 这些复杂的状态管理框架了。
Redux 是学习 React 绕不过的一个框架. 尽管 Redux 的代码只有一百多行,概念却很多,学习曲线非常陡峭,看官方文档就知道了。即使它的实现很简洁,但是开发代码并不简洁(和 mobx 相反, 脏活留给开发者),尤其遵循它的’最佳实践’,是从头开始构建一个项目是非常繁琐的. 还在现在有类似 dva 或 rematch 这样的二次封装库来简化它.
本文不打算深入介绍 Redux 的相关实践, 社区上面有非常多的教程,官方文档也非常详尽. 这里会介绍 Redux 的主要架构和核心思想,以及它的适用场景.
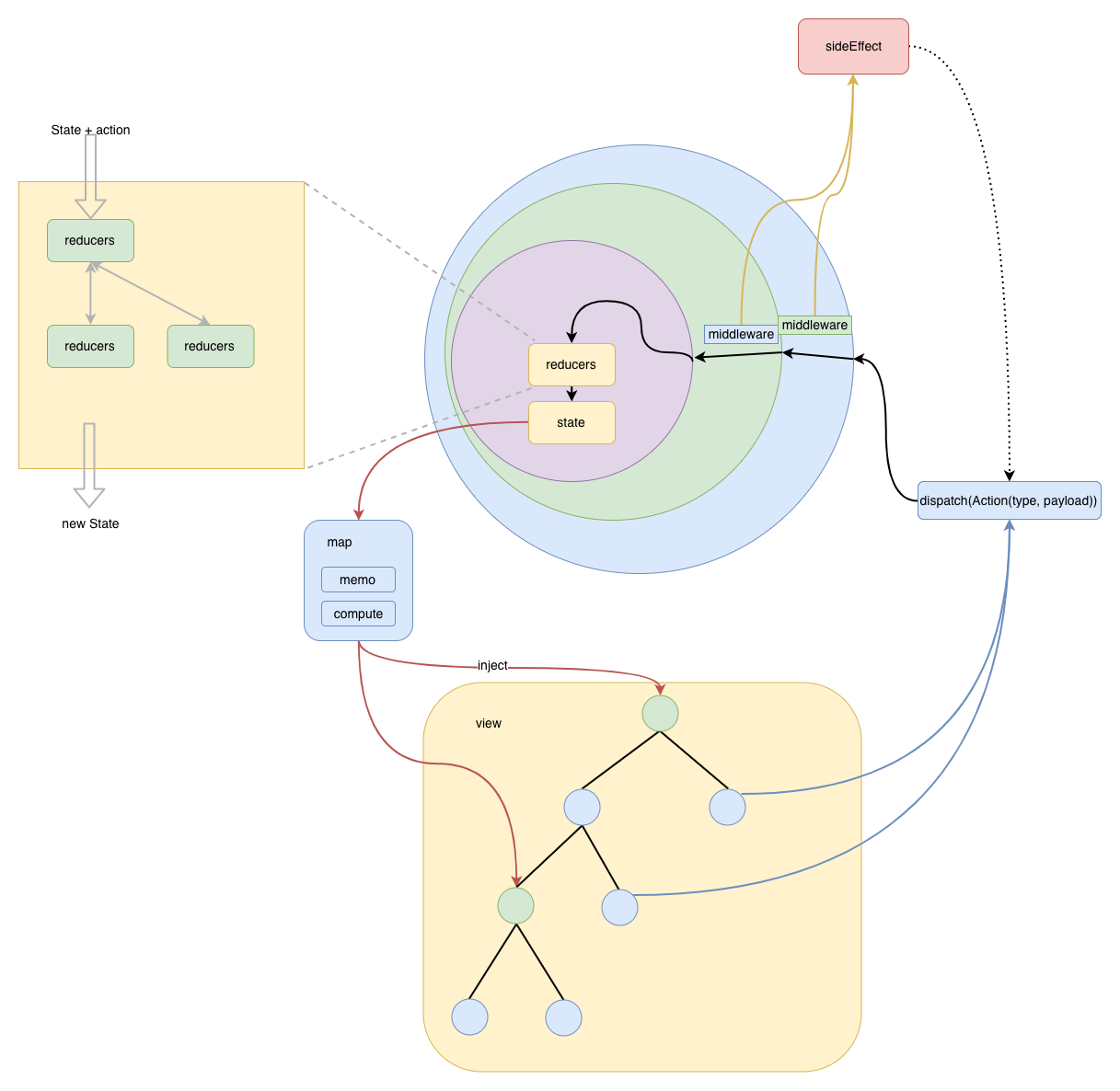
Redux 的主要结构如上,在此之前你先要搞清楚 Redux 的初衷是什么,才能明白它为什么要这么设计. 在我看来 Redux 主要为了解决以下两个问题:
- 可预测状态
- 简化应用数据流
其实这也是 flux 的初衷, 只是有些它有些东西没做好. 明白 Redux 的初衷,现在来看看它的设计就会清晰很多
单一数据源 -> 可预测,简化数据流:数据只能在一个地方被修改
可以简化应用数据流. 解决传统多 model 模型数据流混乱问题(比如一个 model 可以修改其他 model,一个 view 受到多个 model 驱动),让数据变动变得可预测可调试
同构化应用开发
- 方便调试
- 方便做数据镜像. 可以实现撤销/重做、时间旅行、热重载、状态持久化和恢复
单向数据流 -> 简化数据流, 可预测
- 不能直接修改状态 -> 可预测
- 只能通过 dispatch action 来触发状态变更. action 只是一个简单的对象, 携带事件的类型和 payload
- reducer 接收 action 和旧的 state, 规约生成新的 state. reducer 只是一个纯函数,可以嵌套组合子 reducer 对复杂 state 树进行规约
- 不可变数据.
- 可测试.
- 范式化和反范式化. Store 只存储范式化的数据,减少数据冗余。视图需要的数据通过 reselect 等手段反范式化
- 通过中间件隔离副作用 -> 可预测
可以说 Redux 的核心概念就是 reducer,然而这是一个纯函数。为了实现复杂的副作用,redux 提供了类似 Koa 的中间件机制,实现各种副作用. 比如异步请求. 除此之外,可以利用中间件机制,实现通用的业务模式, 减少代码重复。 - Devtool -> 可预测。通过开发者工具可以可视化数据流
什么时候应该使用 Redux?
首先还是警告一下: You Might Not Need Redux, Redux 不是你的第一选择。
当我们需要处理复杂的应用状态,且 React 本身无法满足你时. 比如:
- 你需要持久化应用状态, 这样你可以从本地存储或服务器返回数据中恢复应用
- 需要实现撤销重做这些功能
- 实现跨页面的用户协作
- 应用状态很复杂时
- 数据流比较复杂时
- 许多不相关的组件需要共享和更新状态
- 外置状态
- …
最佳实践
个人觉得react-boilerplate是最符合官方‘最佳实践’的项目模板. 它的应用工作流如下:

特性:
- 整合了 Redux 生态比较流行的方案:
immer(不可变数据变更),redux-saga(异步数据流处理),reselect(选取和映射 state,支持 memo,可复合),connected-react-router(绑定 react-router v4) - 根据页面分割 saga 和 reducer。见下面 👇 和目录结构
- 按需加载 saga 和 reducer(通过 replaceReducer)
- 划分容器组件和展示组件
再看看 react-boilerplate 目录结构. 这是我个人比较喜欢的项目组件方式,组织非常清晰,很有参考意义
/src |
🤬 开始吐槽!
一,Redux 核心库很小,只提供了 dispatch 和 reducer 机制,对于各种复杂的副作用处理 Redux 通过提供中间件机制外包出去。社区有很多解决方案,redux-promise, redux-saga, redux-observable… 查看 Redux 的生态系统.
Redux 中间件的好处是扩展性非常好, 开发者可以利用中间件抽象重复的业务 e 中间件生态也百花齐放, 但是对于初学者则不友好.
TM 起码还得需要去了解各种各样的库,横向比较的一下才知道自己需要搭配哪个库吧? 那好吧,就选 redux-saga 吧,star 数比较多。后面又有牛人说不要面向 star 编程,选择适合自己团队的才是最好的… 所以挑选合适的方案之前还是得要了解各种方案本身吧?。
Vue 之所以学习曲线比较平缓也在于此吧。它帮助我们做了很多选择,提供简洁的解决方案,另外官方还提供了风格指南和最佳实践. 这些选择适合 80%以上的开发需求. 开发者减少了很多折腾的时间,可以专心写业务. 这才是所谓的‘渐进式’框架吧, 对于不爱折腾的或初学者,我们帮你选择,但也不会阻碍你往高级的地方走。 这里可以感受到 React 社区和 Vue 社区的风格完全不同.
在出现选择困难症时,还是看看别人怎么选择,比如比较有影响力的团队或者流行的开源项目(如 dva,rematch),选取一个折中方案, 后续有再慢慢深入研究. 对于 Redux 目前比较流行的组合就是:
immer+saga+reselect二,太多模板代码。比如上面的 react-boilerplate, 涉及五个文件, 需要定义各种 Action Type、Action、 Reducer、Saga、Select. 所以即便想进行一个小的状态变化也需要更改好几个地方:

笔者个人更喜欢类似 Vuex 这种
Ducks风格的组织方式,将模块下的 action,saga,reducer 和 mapper 都组织在一个文件下面:
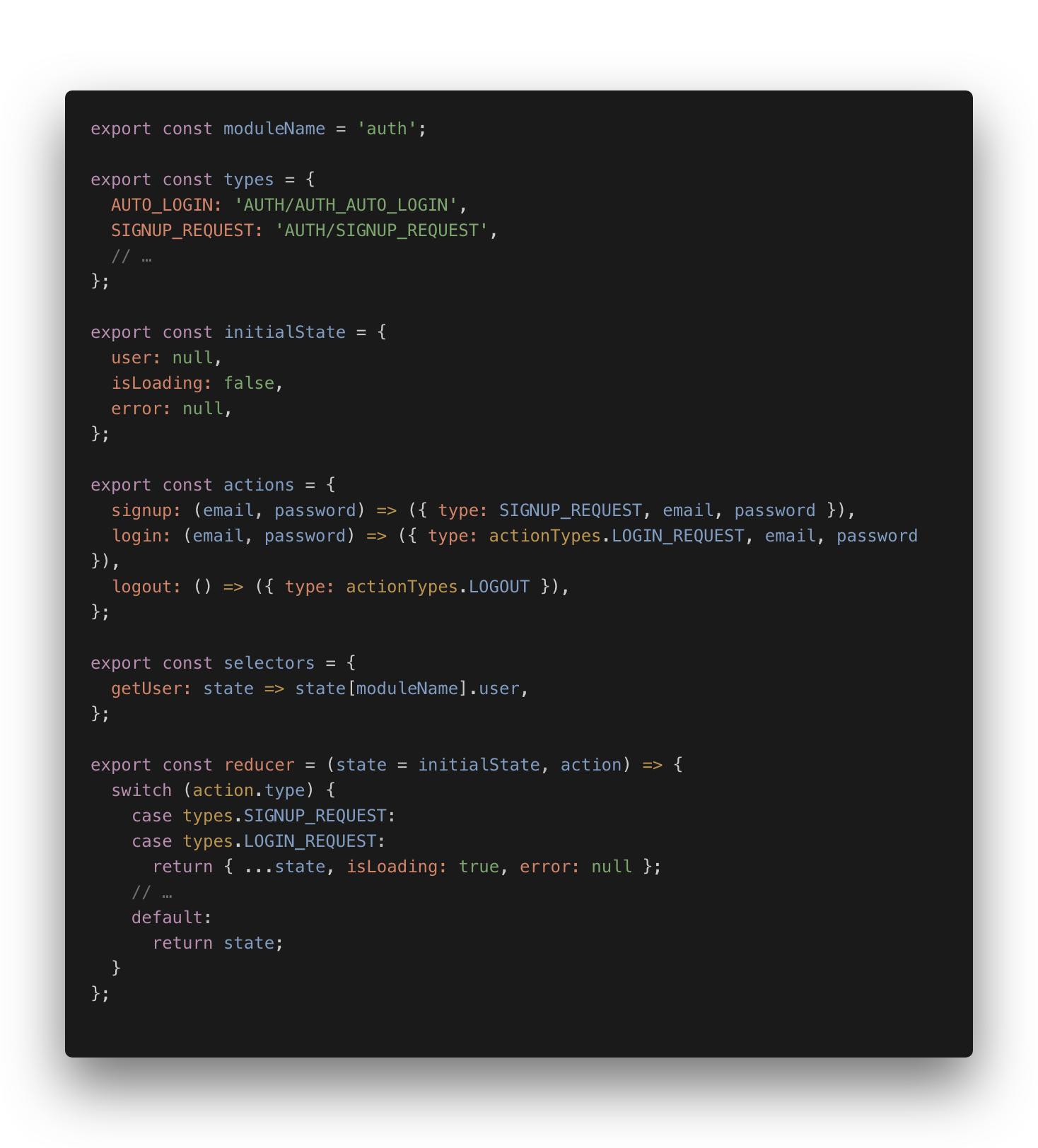
Redux 的二次封装框架基本采用类似的风格, 如
rematch

这些二次封装框架一般做了以下优化(其实可以当做是 Vuex 的优点),来提升 Redux 的开发体验:
- 使用 Ducks 风格组织代码.聚合分散的 reducer,saga,actions…
- 更简化的 API
- 提供了简单易用的模块化(或者称为‘分形’)或者命名空间机制。模块本身支持‘状态隔离’,让模块的 reducer、saga 只专注于模块自己的状态. 另外模块还考虑动态加载
- 内置副作用处理机制。如使用 saga 或 redux-promise
- 简化了不可变数据的操作方式。 如使用 immer
- 简化 reducer。Redux 内置了 combineReducers 来复合多个 reducer,在 reducer 内部我们一般使用 switch 语句来接收 action 和处理数据变动, 其实写起来非常啰嗦. Vuex 和这些封装框架不约而同使用了 key/value 形式, 更为简洁明了
- 简化 view 层的 connect 接口。如简化 mapProps,mapDispatch 这些代码写起来也比较繁琐
三,强制不可变数据。前面文章也提到过 setState 很啰嗦,为了保证状态的不可变性最简单的方式是使用对象展开或者数组展开操作符, 再复杂点可以上 Immutable.js, 这需要一点学习成本. 好在现在有 immer,可以按照 Javascript 的对象操作习惯来实现不可变数据
四,状态设计。
数据类型一般分为领域数据(Domain data)和应用数据(或者称为 UI 数据). 在使用 Redux 时经常需要考虑状态要放在组件局部,还是所有状态都抽取到 Redux Store?把这些数据放到 Redux Store 里面处理起来好像更麻烦?既然都使用 Redux 了,不把数据抽取到 Redux Store 是否不符合最佳实践? 笔者也时常有这样的困惑, 你也是最佳实践的受害者?
我觉得可以从下面几个点进行考虑:
- 领域数据还是应用数据? 领域数据一般推荐放在 ReduxStore 中,我们通常会将 Redux 的 Store 看作一个数据库,存放范式化的数据。
- 状态是否会被多个组件或者跨页面共享? Redux Store 是一个全局状态存储器,既然使用 Redux 了,有理由让 Redux 来管理跨越多组件的状态
- 状态是否需要被镜像化? 如果你的应用要做‘时间旅行(撤销/重做)’或者应用持久化,这个状态需要被恢复,那么应该放到 Redux Store,集中化管理数据是 Redux 的强项
- 状态是否需要跨越组件的生命周期? 将状态放在组件局部,就会跟着组件一起被销毁。如果希望状态跨越组件的生命周期,应该放到父组件或者 Redux Store 中. 比如一个模态框编辑的数据在关闭后是否需要保留
原则是能放在局部的就放在局部. 在局部状态和全局状态中取舍需要一点开发经验.
另外作为一个集中化的状态管理器,为了状态的可读性(更容易理解)和可操作性(更容易增删查改),在状态结构上面的设计也需要花费一些精力的. 这个数据库结构的设计方法是一样的, 在设计状态之前你需要理清各种领域对象之间的关系, 在数据获取和数据变更操作复杂度/性能之间取得平衡.
Redux 官方推荐范式化 State,扁平化结构树, 减少嵌套,减少数据冗余. 也就是倾向于更方便被更新和存储,至于视图需要什么则交由 reselect 这些库进行计算映射和组合.
所以说 Redux 没那么简单, 当然 80%的 Web 应用也不需要这么复杂.
五,不方便 Typescript 类型化。不管是 redux 还是二次封装框架都不是特别方便 Typescript 进行类型推导,尤其是在加入各种扩展后。你可能需要显式注解很多数据类型
六,不是分形(Fractal)
在没有看到@杨剑锋的这条知乎回答之前我也不知道什么叫分形, 我只能尝试解释一下我对分形的理解:
前面文章也提到过‘分离逻辑和视图’和‘分离容器组件和展示组件’,这两个规则都来自于 Redux 的最佳实践。Redux 就是一个’非分形的架构’,如下图,在这种简单的‘横向分层’下, 视图和逻辑(或状态)可以被单独复用,但在 Redux 中却很难将二者作为一个整体的组件来复用:
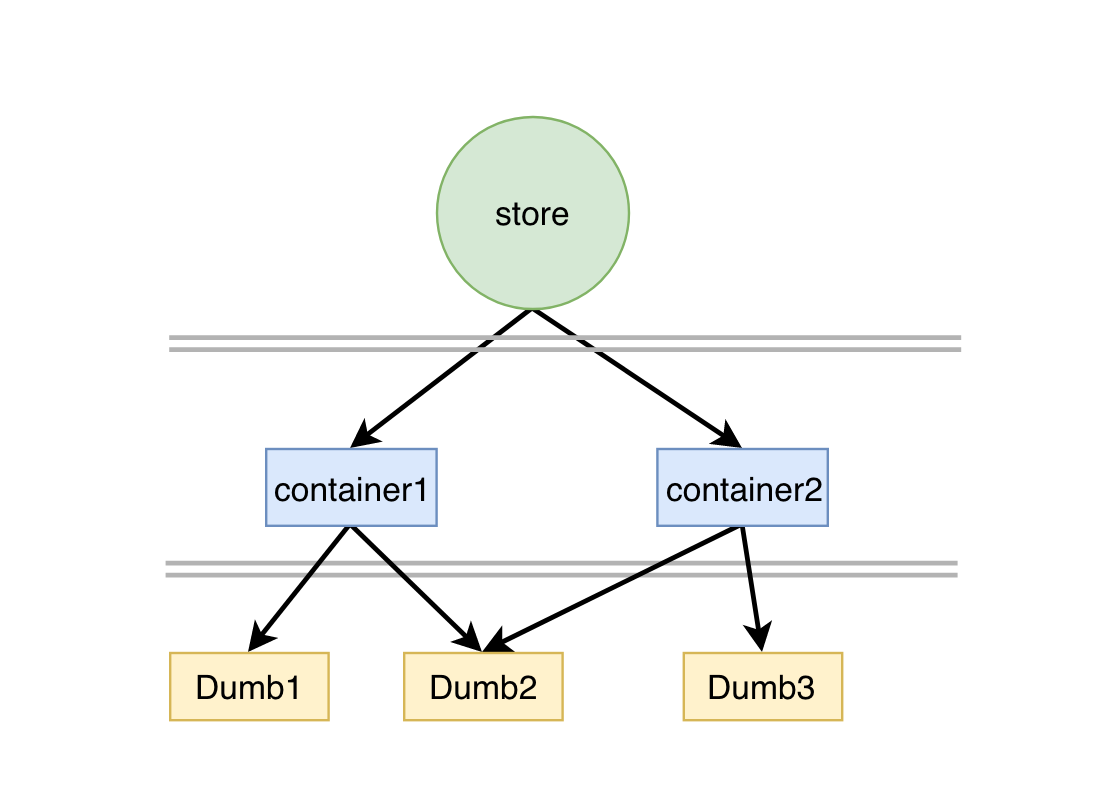
集中化的 Store,再通过 Connect 机制可以让状态在整个应用范围内被复用;Dumb 组件抽离的状态和行为,也容易被复用现在假设你需要将单个 container 抽离成独立的应用,单个 container 是无法独立工作的。在分形的架构下,一个‘应用’有更小的‘应用’组成,‘应用’内部有自己的状态机制,单个应用可以独立工作,也可以作为子应用. 例如 Redux 的鼻祖 Elm 的架构:
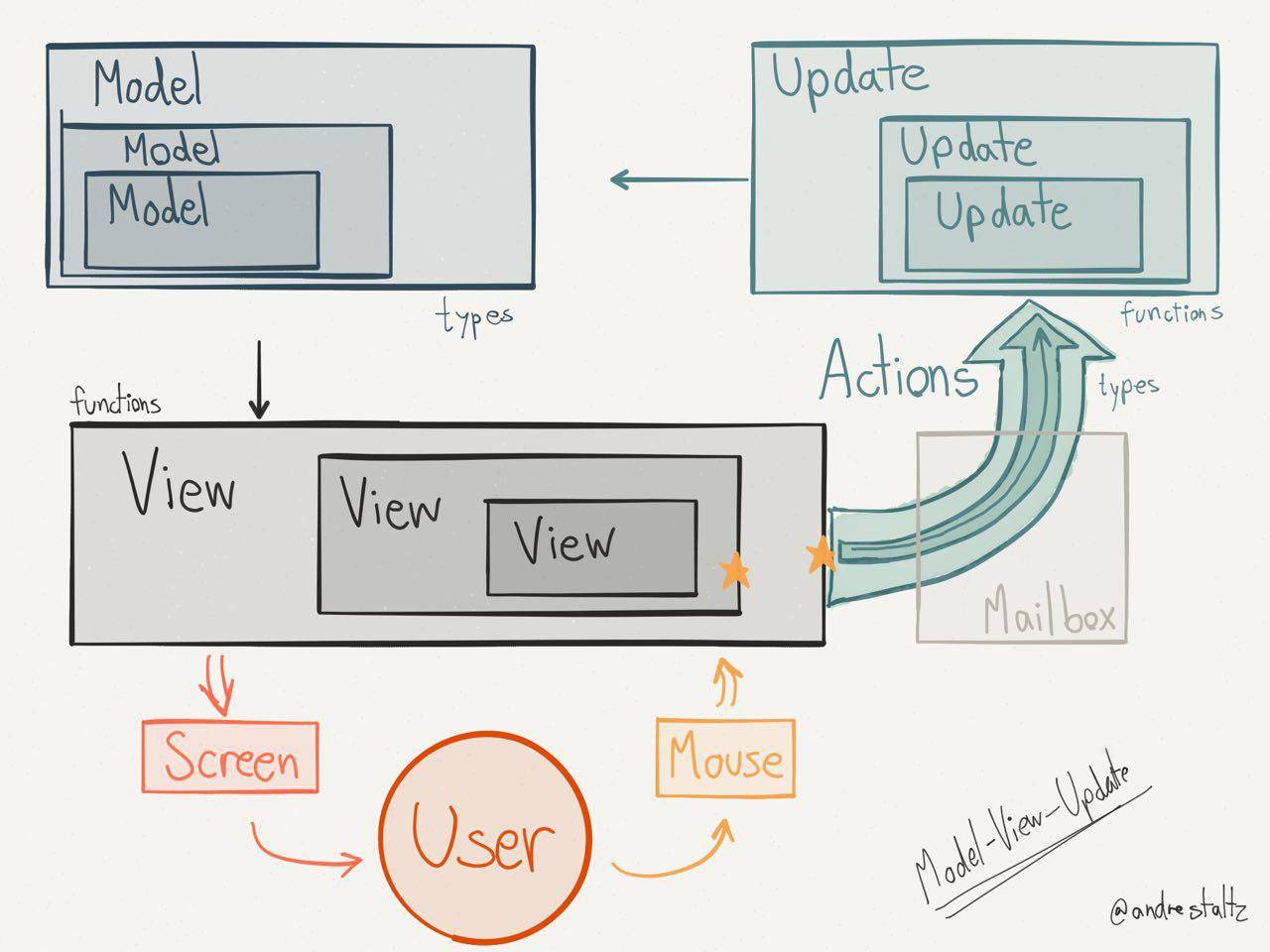
Store的结构和应用的结构保持一致, 每个 Elm 组件也是一个 Elm 应用,包含完整的Action、Update、Model和View. 使得单独的应用可以被复用Redux 不是分形和 Redux 本身的定位有关,它是一个纯粹的状态管理器,不涉及组件的视图实现,所以无法像 elm 和 cyclejs 一样形成一个完整的应用闭环。 其实可以发现 react 组件本身就是分形的,组件原本就是状态和视图的集合.
分形的好处就是可以实现更灵活的复用和组合,减少胶水代码。显然现在支持纯分形架构的框架并不流行,原因可能是门槛比较高。个人认为不支持分形在工程上还不至于成为 Redux 的痛点,我们可以通过‘模块化’将 Redux 拆分为多个模块,在多个 Container 中进行独立维护,从某种程度上是否就是分形?另外这种横向隔离的 UI 和状态,也是有好处的,比如 UI 相比业务的状态变化的频度会更大.
个人感觉到页面这个级别的分化刚刚好,比如方便分工。比如最近笔者就有这样一个项目, 我们需要将一个原生 Windows 客户端转换成 electron 实现,限于资源问题,这个项目涉及到两个团队之间协作. 对于这个项目应用 Store 就是一个接口层,Windows 团队负责在这里维护状态和实现业务逻辑,而我们前端团队则负责展示层. 这样一来 Windows 不需要学习 React 和视图展示,我们也不需要关系他们复杂的业务逻辑(底层还是使用 C++, 暴露部分接口给 node)
七,可能还有性能问题
总结
本节主要介绍的 Redux 设计的动机,以及围绕着这个动机一系列设计, 再介绍了 Redux 的一些缺点和最佳实践。Redux 的生态非常繁荣,如果是初学者或不想折腾还是建议使用 Dva 或 rematch 这类二次封装框架,这些框架通常就是 Redux 一些最佳实践的沉淀, 减少折腾的时间。当然这只是个开始,组织一个大型项目你还有很多要学的。
扩展阅读
- Redux 有什么缺点 知乎上的吐槽
- Redux 状态管理之痛点、分析与改良
- Redux 有哪些最佳实践?
- 如何评价数据流管理架构 Redux?
- 2018 年我们还有什么功能是 Redux 才适合做的吗?
- Cycle.js 状态管理模型
- 使用 Dva 开发复杂 SPA
- Redesigning Redux
- Redux 官方文档
- redux 三重境
Mobx
Mobx 提供了一个类似 Vue 的响应式系统,相对 Redux 来说 Mobx 的架构更容易理解。 拿官方的图来看:
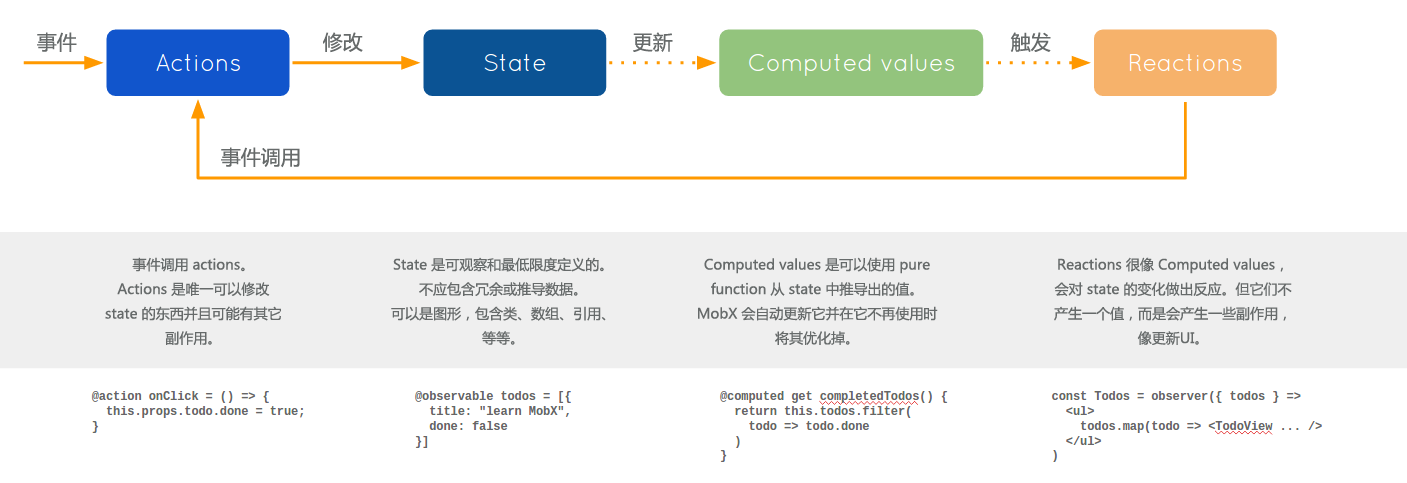
响应式数据. 首先使用
@observable将数据转换为‘响应式数据’,类似于 Vue 的 data。这些数据在一些上下文(例如 computed,observer 的包装的 React 组件,reaction)中被访问时可以被收集依赖,当这些数据变动时相关的依赖就会被通知.响应式数据带来的两个优点是 ① 简化数据操作方式(相比 redux 和 setState); ② 精确的数据绑定,只有数据真正变动时,视图才需要渲染,组件依赖的粒度越小,视图就可以更精细地更新
衍生.
- 衍生数据。Mobx 也推荐不要在状态中放置冗余或可推导的数据,而是使用
@computed计算衍生的状态. computed 的概念类似于 Redux 中的 reselect,对范式化的数据进行反范式化或者聚合计算 - 副作用衍生. 当数据变动时触发依赖该数据的副作用,其中包含‘视图’。视图是响应式数据的映射
- 衍生数据。Mobx 也推荐不要在状态中放置冗余或可推导的数据,而是使用
数据变更. mobx 推荐在
action/flow(异步操作)中对数据进行变更,action 可以认为是 Redux 中的 dispatch+reducer 的合体。在严格模式下 mobx 会限制只能在 action 函数中进行变更,这使得状态的变更可被追溯。推荐在 flow 函数中隔离副作用,这个东西和 Redux-saga 差不多,通过 generator 来进行异步操作和副作用隔离
上面就是 Mobx 的核心概念。举一个简单的例子:
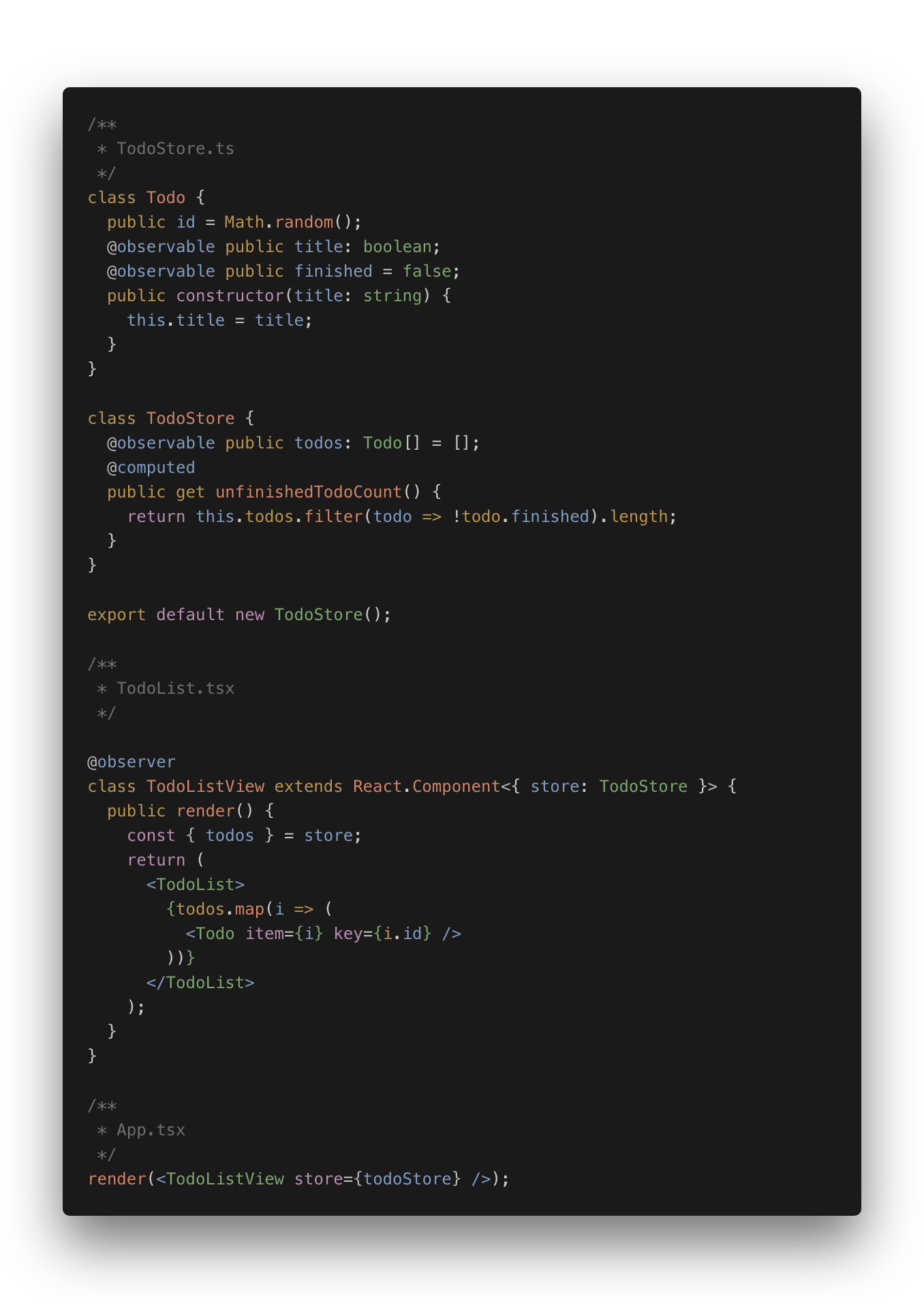
但是Mobx 不是一个框架,它不会像 Redux 一样告诉你如何去组织代码,在哪存储状态或者如何处理事件, 也没有最佳实践。好处是你可以按照自己的喜好组件项目,比如按照 Redux(Vuex)方式,也可以使用面向对象方式组织; 坏处是如果你没有相关经验, 会不知所措,不知道如何组织代码
Mobx 一般使用面向对象的方式对 Store 进行组织, 官方文档构建大型可扩展可维护项目的最佳实践也介绍了这种方式, 这个其实就是经典的 MV* 模式:
src/ |
领域对象
面向对象领域有太多的名词和概念,而且比较抽象,如果理解有误请纠正. 暂且不去理论领域对象是什么,尚且视作是现实世界中一个业务实体在 OOP 的抽象. 具体来说可以当做MVC模式中的 M, 或者是 ORM 中数据库中映射出来的对象.
对于复杂的领域对象,会抽取为单独的类,比如前面例子中的Todo类, 抽取为类的好处是它具有封装性,可以包含关联的行为、定义和其他对象的关联关系,相比纯对象表达能力更强. 缺点就是不好序列化
因为它们和页面的关联关系较弱,且可能在多个页面中被复用, 所以放在根目录的models/下. 在代码层面领域对象有以下特点:
- 定义了一些字段(@observable)和一些领域对象的操作方法(@action), 可能还关联其他领域对象,比如订单会关联用户和产品
- 由 Store 来管理生命周期,或者说 Store 就 Model 的容器, 相当于数据库. Store 通常也是单例
示例
import { observable } from 'mobx'; |
Store
Store 只是一个 Model 容器, 负责管理 model 对象的生命周期、定义衍生状态、封装副作用、和后端接口集成等等. Store 一般是单例. 在 Mobx 应用中一般会划分为多个 Store 绑定不同的页面。
示例
import { observable, computed, reaction } from 'mobx'; |
根 Store
class RootStore { |
<Provider rootStore={new RootStore()}> |
看一个 真实世界的例子
这种传统 MVC 的组织方式主要有以下优点:
- 好理解, 容易入手. 经典的 MVC 模式、面向对象,我们再熟悉不过了. 尤其是熟悉 Java 这些传统面向对象编程范式的后端开发人员. 上文提到的跨团队的项目,我们选择的就是 mobx 作为状态管理器,对于他们来说这是最好理解的方式. 但是对于领域对象和领域 Store 的拆分和设计需要一点经验
- 强类型
- 代码简洁。相对 Redux 多余的模板代码而言
- 数据封装性。使用类表达的数据结构可以封装相应的行为
问题
- 在多个 Store 之间共享数据比较麻烦. 我们的做法是让所有 Store 都继承一个父类作为中间者,通过事件订阅模式在多个 Store 间进行数据通信
- 缺乏组织。相对 Redux 而言, 状态过于零散,不加以约束,状态可以被随意修改。我们很多代码就是这样,懒得写 action,甚至直接在视图层给状态赋值. 所以一定要开始严格模式
- 没有 Magic. 这是一把双刃剑, Redux 有中间件机制,可以扩展抽象许多重复的工作, 比如为异步方法添加 loading 状态, 但是对 Typescript 不友好; 基于类的方案,无处下手,代码会比较啰嗦, 但更直观
- 无数据快照,无法实现时间回溯,这是 Redux 的强项,但大部分的应用不需要这个功能; 另外可以通过 mobx-state-tree 实现
- 无法 hot-reload
还有一些 mobx 本身的问题, 这些问题在上一篇文章也提过, 另外可以看这篇文章(Mvvm 前端数据流框架精讲):
组件侵入性. 需要改变 React 组件原本的结构, 例如所有需要响应数据变动的组件都需要使用 observer 装饰. 组件本地状态也需要 observable 装饰, 以及数据操作方式等等. 对 mobx 耦合较深, 日后切换框架或重构的成本很高
兼容性. mobx v5 后使用 Proxy 进行重构, 但 Proxy 在 Chrome49 之后才支持. 如果要兼容旧版浏览器则只能使用 v4, v4 有一些坑, 这些坑对于不了解 mobx 的新手很难发现:
- Observable 数组并非真正的数组. 比如 antd 的 Table 组件就不认 mobx 的数组, 需要传入到组件之间使用 slice 进行转换
- 向一个已存在的 observable 对象中添加属性不会被自动捕获
MV* 只是 Mobx 的其中一种主流组织方式, 很多文章在讨论 Redux 和 mobx 时往往会沦为函数式和面向对象之争,然后就下结论说 Redux 更适合大型项目,下这种结论最主要的原因是 Redux 有更多约束(only one way to do it), 适合项目的演进和团队协作, 而不在于函数式和面向对象。当然函数式和面向对象范式都有自己擅长的领域,例如函数式适合数据处理和复杂数据流抽象,而面向对象适合业务模型的抽象, 所以不要一竿子打死.
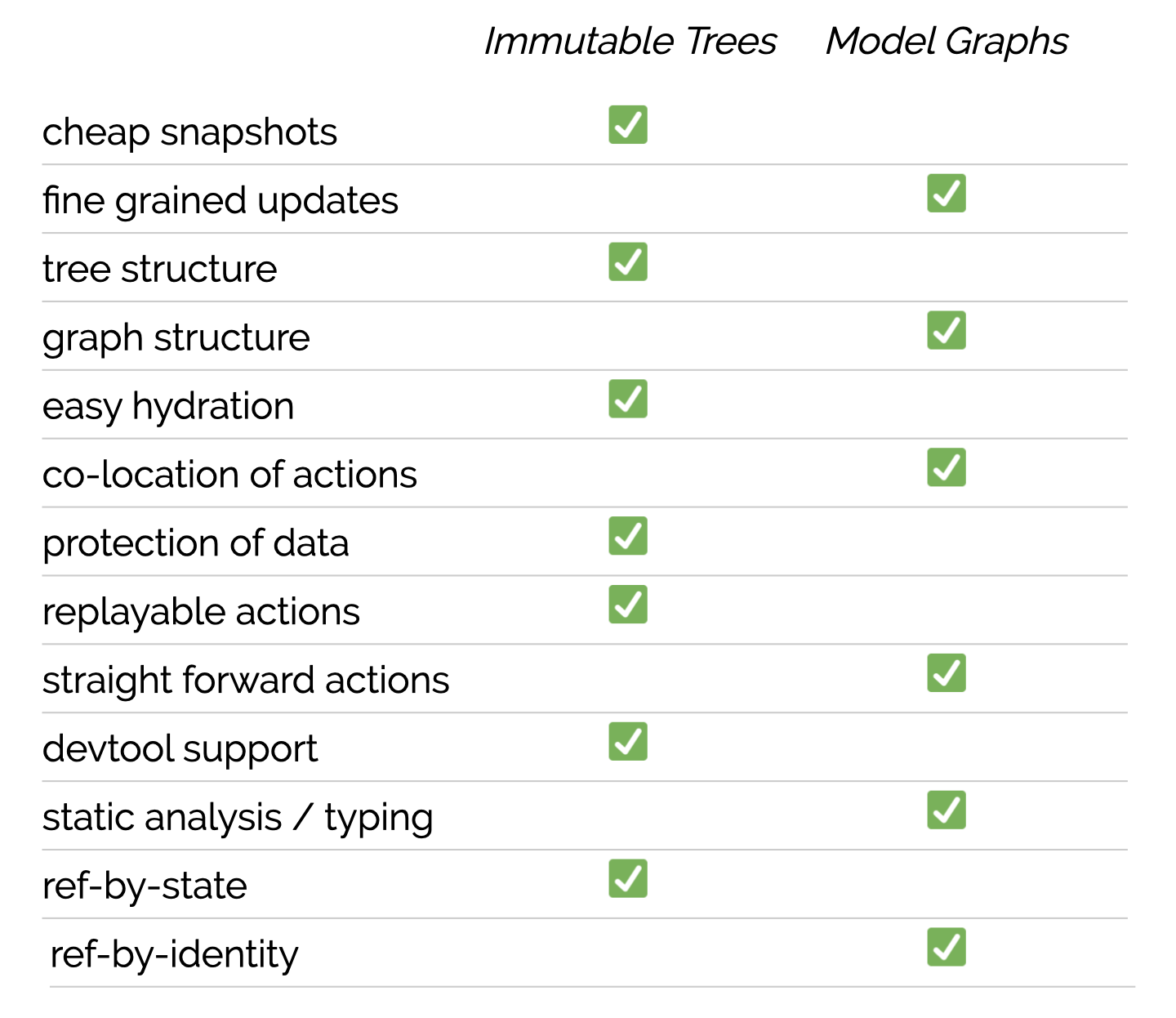
换句话说适不适合大型项目是项目组织问题, Mobx 前期并没有提出任何解决方案和最佳实践。这不后来其作者也开发了mobx-state-tree这个神器,作为 MobX 官方提供的状态模型构建库,MST 吸收了 Redux 等工具的优点,旨在结合不可变数据/函数式(transactionality, traceability and composition)和可变数据/面向对象(discoverability, co-location and encapsulation)两者的优点, 提供了很多诸如数据镜像(time travel)、hot reload、action middleware、集成 redux-devtools 以及强类型(Typescript + 运行时检查(争议点))等很有用的特性, 其实它更像是后端 ActiveRecord 这类 ORM 工具, 构建一个对象图。
典型的代码:
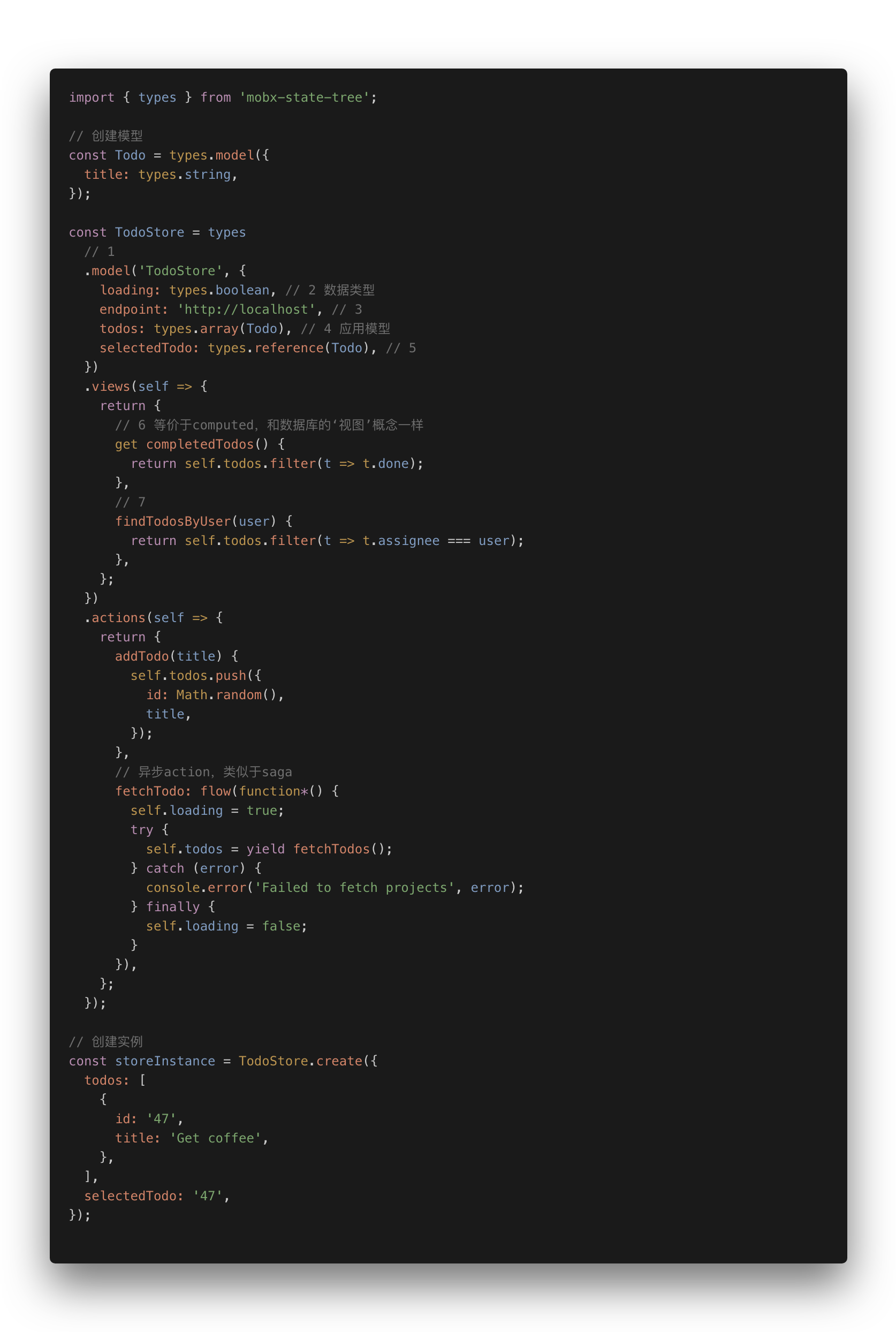
限于笔者对 MST 实践不多,而且文章篇幅已经很长,所以就不展开了,后续有机会再分享分享。
还是得下一个结论, 选择 Mobx 还是 Redux? 这里还是引用来自MobX vs Redux: Comparing the Opposing Paradigms - React Conf 2017 纪要的结论:
- 需要快速开发简单应用的小团队可以考虑使用 MobX,因为 MobX 需要开发的代码量小,学习成本低,上手快,适合于实时系统,仪表盘,文本编辑器,演示软件,但不适用于基于事件的系统
- Redux 适用于大团队开发复杂应用,Redux 在可扩展性和可维护性方面可以 hold 住多人协作与业务需求多变,适合商业系统、基于事件的系统以及涉及复杂反应的游戏场景。
上述结论的主要依据是 Redux 对 action / event 作出反应,而 MobX 对 state 变化作出反应。比如当一个数据变更涉及到 Mobx 的多个 Store,可以体现出 Redux 的方式更加优雅,数据流更加清晰. 前面都详尽阐述了 Mobx 和 Redux 的优缺点,mobx 还有 MST 加持, 相信读者心里早已有自己的喜好
扩展
- 你需要 Mobx 还是 Redux?
- Mobx 思想的实现原理,及与 Redux 对比
- MobX vs Redux: Comparing the Opposing Paradigms - React Conf 2017 纪要
- dob 更轻量的类似 mobx 的轮子
- 积梦前端采用的 React 状态管理方案: Rex
- 干货 | Mvvm 前端数据流框架精讲
RxJS
如果上文提到的状态管理工具都无法满足你的需要,你的项目复杂程度可能超过全国 99%的项目了. RxJS 可能可以助你一臂之力, RxJS 非常适合复杂异步事件流的应用,笔者在这方面实践也比较少,推荐看看徐飞的相关文章, 另外 Redux(Redux-Observable)和 Mobx 实际上也可以配合 RxJS 使用
其他状态管理方案
- Apollo+GraphQL
- freactal
推荐这篇文章State of React State Management for 2019